Mongo学习笔记
Mongo学习笔记
[TOC]
一、背景
上周 AOS2 正式上线,迁移了全量的历史数据,总共向 MongoDB 中写入了十几亿条数据,基本都是 cpu 顶格着写的。
刚刚刷到了一个 MongoDB 教学的小视频,刚好可以对照着写数据时的监控深入学习一下。
二、知识点
视频核心知识点总结:MySQL vs MongoDB 及 MongoDB 架构详解
1. 为什么需要MongoDB?
- 场景痛点:游戏平台需存储十多亿用户数据,包含动态扩展字段(如节日活动参与状态)。若用MySQL,需提前定义表结构并预留大量冗余字段,导致空间浪费和迭代成本高(每次新增活动需修改表结构)。
- MongoDB 优势:灵活的文档存储(类似 JSON),无需预定义结构,支持动态添加字段,适合高频迭代的业务场景。
2. MongoDB核心概念
- 文档(Document):替代 MySQL 的 “行”,数据以JSON-like格式存储,字段可动态增减。例如:
1
2
3
4
5
{
"_id": "user123",
"装备": ["剑", "盾"],
"参与活动": {"春节": true, "情人节": false}
}
-
集合(Collection):替代 MySQL 的 “表”,由多个文档组成,无需统一字段。
-
与MySQL对比:
| MySQL | MongoDB |
|---|---|
| 行+列,结构固定 | 文档+集合,结构灵活 |
| 预定义表结构 | 动态字段扩展 |
| 适合结构化数据 | 适合半结构化/非结构化数据 |
3. MongoDB底层存储与索引
存储引擎:
- 默认使用 WiredTiger,支持高效读写。
- 存储文件:后缀为 .wt 的文件,BSON 格式,支持二进制读写。
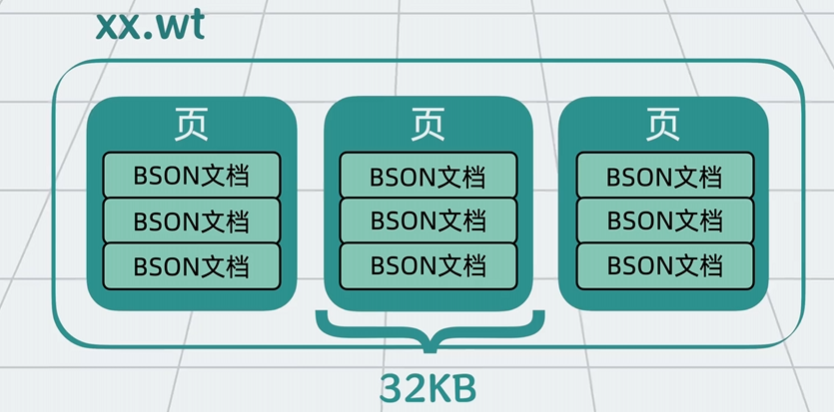
-
数据页:每个文档存储在 32KB 的数据页中,减少 I/O 开销。
-
B+ 树索引:
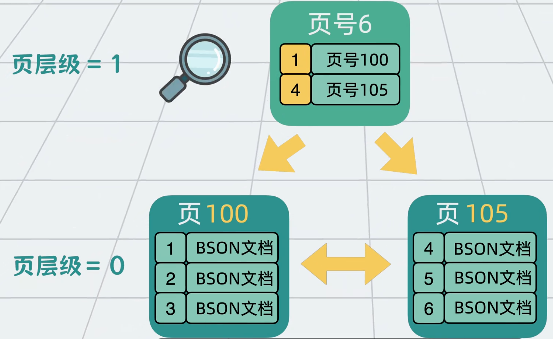
- 主索引:基于文档
_id构建,加速定位。 - 辅助索引:支持其他字段(如用户名)的快速查询。
- 主索引:基于文档
-
写时复制(COW - CopyOnWrite):写入时复制数据页,避免锁竞争,提升并发性能。从这个角度看,本质上其实是个变种 B+ 树。
缓存机制:
- 内存缓存(Cash):缓存热点数据页,查询优先命中内存。MongoDB 会把经常访问的热点数据页放到 Cache 里,查询优先查 Cache,查不到再去查磁盘,这样磁盘 IO 变少,整体查询速度就会变快。
- LRU 策略:自动淘汰最少使用的数据,平衡内存占用。为了保证内存不被占满,需要根据一些策略删除一些内存,比如将最近使用最少的内存删掉,这就叫 LRU(Least Recently Used)。这样不仅可以解决内存过大的问题,还能保证内存中都是热点数据。
持久化保障:
-
写前日志(Journal):记录所有写操作,崩溃后可通过日志恢复数据。
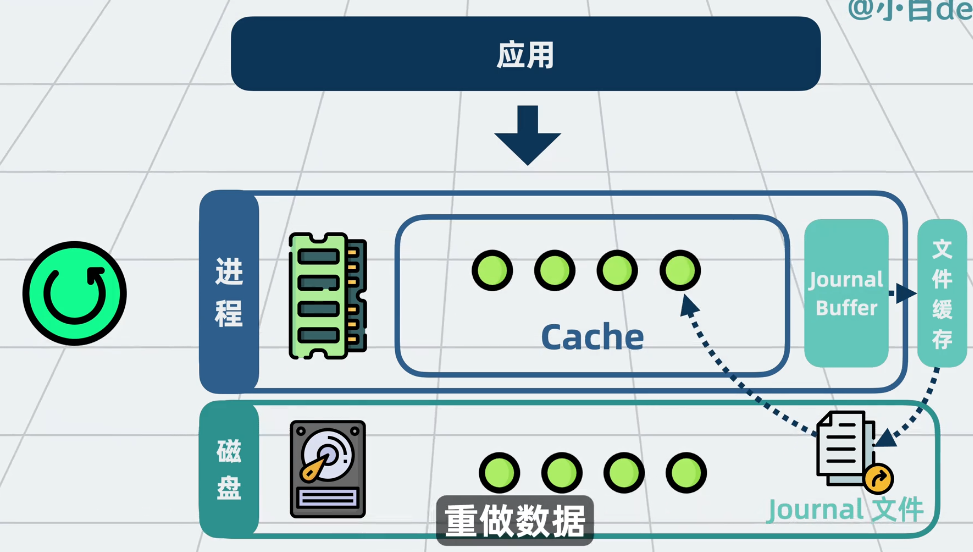
-
CheckPoint:定期把 Cache 中已修改但未写入磁盘的数据页(称为 “脏页-dirty”)一次性批量写入磁盘。写入后,把之前记录的 Journal 日志删掉。
WiredTiger 存储引擎
上面提到的这一整套文件存储类型、B+ 树索引、缓存机制、持久化保障,统一构成了 WiredTiger 引擎。
WiredTiger 是一款高性能、高度可扩展的开源数据库存储引擎,主要运行在大规模、高并发的生产环境中。它由 Grammarscope 公司开发,现已被 MongoDB 收购,并从 MongoDB 3.2 版本开始成为 MongoDB 的默认存储引擎。
- 主要特点:
- ACID事务支持:保证事务的原子性、一致性、隔离性和持久性,能够处理高并发请求,并减少竞争条件的发生。
- 内存映射文件缓存:将经常访问的数据缓存到内存中,使用内存映射文件缓存技术,大大减少磁盘I/O的次数,提升读写速度。
- B+ 树索引优化:使用B树索引来优化索引读取性能,提升磁盘页面的数据访问。
- 可压缩性:可以存储和查询压缩的数据,从而节省磁盘空间和提高读写性能。
- 支持多版本并发控制(MVCC):实现多版本并发控制来处理读写锁等并发问题,避免数据竞争和锁等问题影响性能。
- 在MongoDB中的应用:
- 文档级别的并发控制:在执行写操作时,WiredTiger存储引擎会在文档级别进行并发控制。同一时间点上,多个写操作能够修改同一个集合中的不同文档;而当多个写操作修改同一个文档时,必须以序列化方式执行。
- 事务特性与快照隔离级别:MongoDB支持事务,且符合ACID事务的标准特性。默认使用快照形式的隔离级别,任何事务开始时,会对内存里所有未完成的写操作事务进行拍照,并记录其状态信息。写操作事务在写入前需判断是否与其他未完成事务冲突,若冲突则执行失败,一段时间后重新提交。
- Checkpoint 机制:默认每60秒或当日志文件达到2GB时,会产生一次checkpoint。其作用是在恢复数据库时,只需从最新的checkpoint时间点进行恢复,缩减恢复时间;同时释放内存“脏页”所占的内存空间。
- 内存使用:WiredTiger对内存的使用分为内部内存和文件系统缓存两部分。内部内存默认值为{50% of(RAM - 1GB), or 256MB},索引和集合的内存都被加载到内部内存,索引被压缩,集合未压缩。文件系统缓存会自动使用其他所有空闲内存,其中的数据与磁盘上的数据格式一致,可有效减少磁盘I/O。
4. MongoDB Server层架构
- 连接管理:处理客户端网络连接。
- 查询解析器:验证查询语法(如字段名是否正确)。
- 查询优化器:选择最优索引,生成执行计划。
- 执行器:根据执行计划,调用 WiredTiger 接口执行操作。
- 解耦设计:Server 层与存储引擎通过接口通信,支持替换存储引擎(如早期使用 mmapv1)。
5. 分布式 MongoDB 集群
- 分片(Sharding):按
_id范围拆分数据到多个节点(node),如 0-1000 万放节点 A,1000万-2000 万放节点 B,每个节点只处理 1kw 条数据。每个节点都包含对应的分片。 - 路由服务(Mongos):客户端请求的入口,负责路由到对应分片并合并结果。
- 配置服务器(Config Server):存储分片元数据(如数据范围、节点信息)。每个分片都会链接 Config Server,并主动上报自身信息。
- 副本集(Replica Set):每个分片包含主节点和多个副本,主节点故障时自动选举新主节点,保障高可用。类似于 MySQL 的主从模式。另外副本节点也可以同时对外提供读取功能。
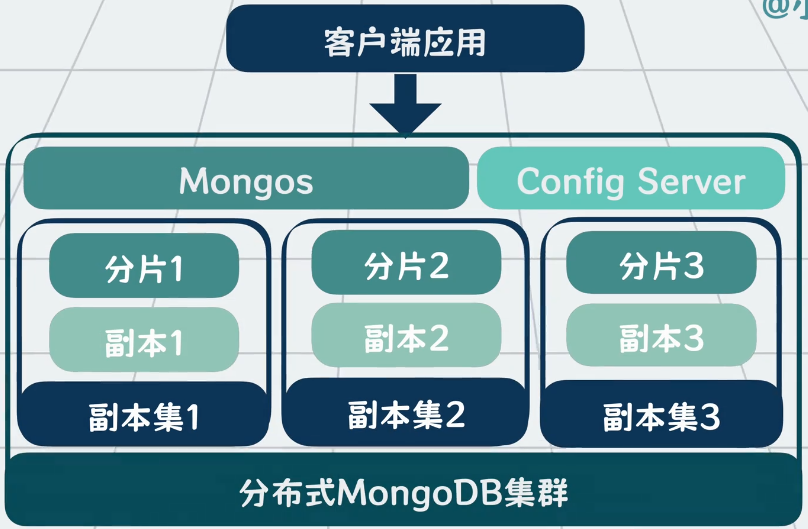
在上述架构中:分片、路由、配置,保证了 MongoDB 的高扩展性;副本集架构保证了 MongoDB 的高可用。
6. 完整数据流程
- 读操作:
- 客户端 → Mongos → 根据分片信息路由到对应分片。
- 分片 Server 层解析查询 → WiredTiger 检查缓存 → 命中则返回,否则读磁盘。
- 结果合并后返回客户端。
- 写操作:
- 客户端 → Mongos → 路由到对应分片。
- 分片 Server 层记录 Journal → 复制数据页 → 写入新数据页。
- 主节点同步数据到副本 → 所有节点确认后返回成功。
7. 总结对比
| 特性 | MySQL | MongoDB |
|---|---|---|
| 结构 | 强结构化 | 灵活文档 |
| 扩展 | 垂直扩展为主 | 分布式分片 |
| 并发 | 锁粒度细(行锁) | 写时复制无锁 |
| 场景 | 传统OLTP(如电商订单) | 高并发、动态字段(如社交、游戏) |
三、监控现象与原理
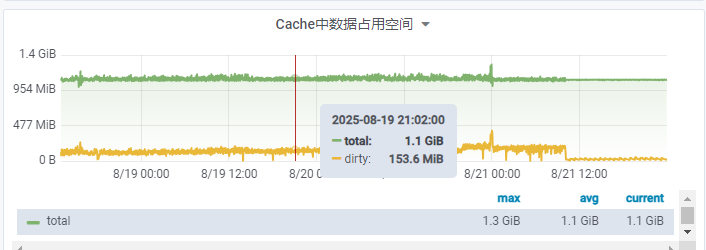
- MongoDB 写入时的 CheckPoint 机制:系统会定期把 Cache 中已修改但为写入磁盘的数据页(称为 “脏页-dirty”)一次性批量写入磁盘。写入后,会把之前记录的 Journal 日志删掉。
- 从监控可以看到,在大量写入时,Cache 的变化很快(曲线尖刺很多),dirty 的量也始终保持在一个较高的量;而在大量写入后,dirty 的量也急剧下降,说明正常业务场景下,写入量其实是很小的。
本文由作者按照
CC BY 4.0
进行授权