Vs里的unicode与多字节
[TOC]
1 “Unicode字符集” 与 “多字节字符集”
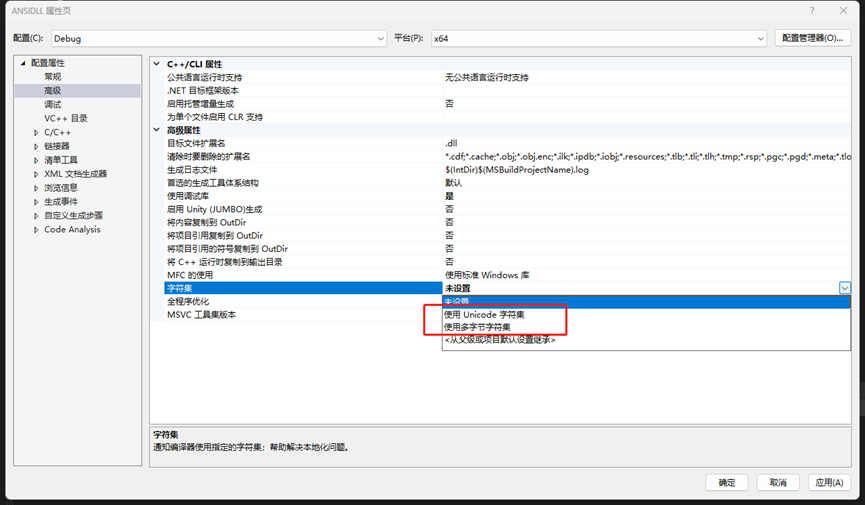
VS 集成开发环境,字符集可以选择 “使用多字节字符集” 和 “使用Unicode字符集” 两种,直接区别就是编译器会增加对应的宏定义。
使用 Unicode 字符集会增加宏定义:“_UNICODE” 和 “UNICODE”;使用多字节字符集会增加宏定义 “_MBCS”。见下面的截图。
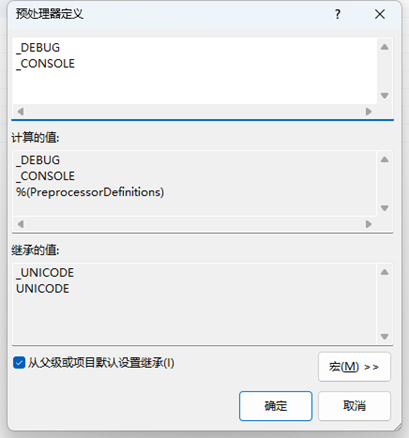 使用 Unicode 字符集
使用 Unicode 字符集
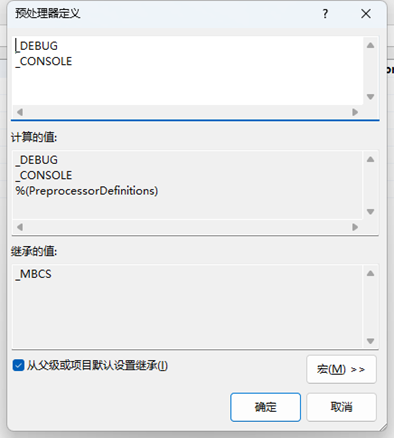 使用使用多字节字符集
使用使用多字节字符集
1.1 宏定义“UNICODE”
该宏定义影响了一些 Windows API 的使用,决定了有字符串参数的 Windows API 使用的是 多字节字符集 还是 宽字符字符集。
例如 MessageBox(),当选用 “使用Unicode字符集” 时,调用函数 MessageBox(),实际使用的是MessageBoxW(),MessageBoxW()关于字符串的入参类型是LPCWSTR,使用MessageBox()时,字符串前需加 L。
1
MessageBox(NULL, L“这是一个测试程序!”, L“Title”, MB_OK);
当选用 “使用多字节字符集” 时,调用函数 MessageBox(),实际使用的是 MessageBoxA(),MessageBoxA() 关于字符串的入参类型是 LPCSTR。
1
MessageBox(NULL, “这是一个测试程序!”, “Title”, MB_OK);
见下面的宏定义:
1
2
3
4
5
#ifdef UNICODE
#define MessageBox MessageBoxW
#else
#define MessageBox MessageBoxA
#endif // !UNICODE
同样的例子还有例如OutputDebugString()等微软提供的函数或宏定义。
1.2 宏定义 “_UNICODE” 与 “_MBCS”
这两个宏定义是用于 C 运行库和 MFC 的,主要影响到 tchar.h 中定义的文本数据类型和具有 _tcs 前缀的函数。
TCHAR 是tchar.h中新定义的一种类型,该数据类型在 tchar.h 中被有条件地定义。如果定义了符号 _UNICODE,则TCHAR定义为 wchar_t ;否则,对于单字节和 MBCS 生成,则将其定义为 char 1。还有其他类似的类型例如_TCHAR、_TINT、_TXCHAR、_T等。
具有_tcs前缀的函数则根据定义的宏映射到str、_mbs或wcs函数2。若要生成 MBCS,请定义符号 _MBCS。 若要生成 Unicode,请定义符号 _UNICODE。 若要生成单字节应用程序,则两者都不定义(默认设置)1。
TCHAR数据类型与_tcs前缀的函数相对应,例如,_tcsncpy() 是复制 n 个 TCHAR,而不是 n 个字节 1。以下代码片以_tcsrev()函数(功能是字符串颠倒)为例,说明了用于映射到 MBCS、Unicode 和 SBCS 模型的 TCHAR 数据类型和 _tcsrev() 函数的使用方法:1
1
2
3
TCHAR *RetVal;
TCHAR szString[256] = _T(“test测试文字”);
RetVal = _tcsrev(szString);
如果定义了 _MBCS,则预处理器将此片段映射到以下代码:
1
2
3
char *RetVal;
char szString[256] = “test测试文字”;
RetVal = _mbsrev(szString);
如果定义了 _UNICODE,则预处理器将此片段映射到以下代码:
1
2
3
wchar_t *RetVal;
wchar_t szString[256] = L“test测试文字”;
RetVal = _wcsrev(szString);
如果 _MBCS 和 _UNICODE 均未定义,则预处理器将片段映射到单字节 ASCII 代码,如下所示:
1
2
3
char *RetVal;
char szString[256] = “test测试文字”;
RetVal = strrev(szString);
还有很多其他类似的函数,例如_tcscmp()(功能是对比两个字符串)、_tcsset()(将一个字符串中的所有字符都设为指定字符)、_tcstok()(分割字符串)等函数。
其中,尽管_mbs的函数与str函数的入参均为char*,但str函数内部是针对 字节(byte)进行操作,而_mbs函数是针对 字符 进行操作的,因此在_MBCS下直接使用str函数也是不安全的。
但是即使含有_MBCS宏定义的情况下,有的_tcs函数也会直接转为str函数而非_mbs函数,例如:_tcscat()(字符串拼接)、_tcscpy()(计算字符串的元素个数)等函数。
在tchar.h中,我找到了一句对这种情况进行的说明的注释:
1
2
3
/*Note that _mbscat, _mbscpy and _mbsdup are functionally equivalent to strcat, strcpy and strdup, respectively.*/
/*注意mbscat、mbscpy和_mbsdup在功能上分别等同于strcat、strcpy和strdup。*/
基于上述注释,我认为,所有不需要按照 字符内容 对字符串进行操作的功能函数,str函数与_mbs函数的实现是一致的,因此在_MBCS中可以直接使用str函数。例如字符串拼接、字符串复制、计算占用字节数等功能,即使不知道每个字节是否对应一个字符,直接挨个儿操作每个字节也能完成对应的功能。而有的功能,例如前面提到的字符串颠倒、字符串对比、字符串分割等功能,都是基于字符实现的功能,而有的字符是占用两个字节的,在这种情况下,就不能使用基于字节实现的str函数,而需要使用基于字符的_mbs函数了。
1.3 输出流对象
(1) cout 与 cin
cout与cin是标准输出流与标准输入流对象,用于输出/输入普通的字符数据,即多字节字符数据。cout将该字符数据输出到控制台或其他输出设备,cin则是从控制台或其他标准输入设备中取得数据。这个无需多余赘述,见下面代码示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
#include <iostream>
using namespace std;
void main()
{
char szChar[9] = "测试test";
cout << "字符内容:" << szChar << endl;
// 计算字符串的长度:
int nszNum = strlen(szChar); // 字符串的元素个数为9(占用的存储单元的个数)
int nszByteNum = nszNum * sizeof(char); // 字符串占用的字节数
// 测试cin:
char szCharIn[256] { ‘\0’ };
cin << szCharIn; // 等待输入
cout << szCharIn << endl; // 将刚才输入的字符串再输出出去
}
(2) wcout
wcout和wcin是宽字符输出流,与用于多字节字符集的cout和cin相对应。用于输出/输入宽字符数据,即UTF-16编码的字符数据。
使用wcout输出宽字节字符的示例代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <iostream>
using namespace std;
void main()
{
/*setlocale(LC_ALL, "chs");*/
// 将wcout的本地化语言设置为中文:
locale oldLocaleCout = wcout.imbue(locale("chs"));
// 将wcin的本地化语言设置为中文:
locale oldLocaleCin = wcin.imbue(locale("chs"));
// 测试wcout:
wchar_t wszChar[7] = L"test测试";
wcout << L"字符串内容:" << wcChar1 << endl;
// 计算字符串长度:
int nWszNum = wcslen(wszChar); // 字符串的元素个数为7(占用的存储单元的个数)
int nWszByteNum = nWszNum * sizeof(wchar_t); // 字符串占用的字节数
// 测试wcin:
wchar_t wszCharIn[256] { ‘\0’ };
wcin << wszCharIn; // 等待输入
wcout << wszCharIn << endl; // 将刚才输入的字符串再输出出去
system("pause");
}
可以发现,在宽字符输出流中,除了需要用wcout,还需要将本地化语言设置为中文。也就是代码:
1
2
3
wcout.imbue(locale("chs"));
wcin.imbue(locale("chs"));
什么是 imbue:3
imbue函数是指对象引用,表示输出时,使用的区域语言对象。
函数原型:locale basic_ios::imbue(const locale& _Loc)
_Loc参数说明:const 对象引用,表示输出时,使用的区域语言对象。
返回值:之前的使用的区域语言。
什么是 locale:
C/C++ 程序中,locale 将决定程序所使用的当前语言编码、日期格式、数字格式及其它与区域有关的设置,locale设置的正确与否将影响到程序中字符串处理(wchar_t如何输出、strftime()的格式等)。因此,对于每一个程序,都应该慎重处理locale设置。C 中的locale和 C++ 中的locale是独立的。3
C 中的locale用setlocale(LC_CTYPE, "")初始化,C++ 中的locale用std::locale::global(std::locale(""))初始化。4
这样就可以根据当前运行环境正确设置locale。
1.4 _T() 或 TEXT() 宏
_T()或者TEXT()宏,可以把你用引号括起来的字符串,根据你的环境选择合适的编码方式:
如果定义的是 Unicode ,那么 _T("abc") 就相当于 L"abc",就是宽字符;
如果是多字节编码,那么 _T("abc") 就相当于 "abc"。也就是英文采用单字节,中文则用双字节编码。
2 字符串长度
本文 1.3 的两段测试代码中分别用strlen()和wcslen()计算了字符串的元素个数,这两个函数其实可以用同一个函数定义_tcslen()来代替,这一点在本文 1.2 中已经提到了。
这里想强调的是,这两个函数返回的都是字符串占用的 元素个数,也就是有几个TCAHR,也可以说成是 存储单元的个数 。而非字节个数或字符个数。
对于同样的文本内容 “test测试”:
在 “Unicode字符集” 下的测试代码和各函数的返回值为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// 测试wchar_t:
wchar_t wszChar[256] = L"test测试";
// 字符串占用的存储单元个数,此处为6
int nWszNum = wcslen(wszChar);
// 字符串占用的字节数,此处为12
int nWszByteNum = nWszNum * sizeof(wchar_t);
// 测试CString:
CString strTest = L"test测试";
// 字符串占用的存储单元个数,此处为6
int nStrLength = strTest.GetLength();
// 测试wstring:
std::wstring wsTest = L"test测试";
// 字符串占用的存储单元个数,此处为6
int nwsLength = wsTest.length();
// 字符串占用的存储单元个数,此处为6
int nwsSize = wsTest.size();
在 “多字节字符集” 下的测试代码即各函数的返回值为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// 测试char:
char szChar[256] = "test测试";
// 字符串占用的存储单元个数,此处为8
int nszNum = strlen(szChar);
// 字符串占用的字节数,此处为8
int nszByteNum = nszNum * sizeof(char);
// 测试CString:
CString strTest = "test测试";
// 字符串占用的存储单元个数,此处为8
int nStrLength = strTest.GetLength();
// 测试string:
std::string sTest = "test测试";
// 字符串占用的存储单元个数,此处为8
int nsLength = sTest.length();
// 字符串占用的存储单元个数,此处为8
int nsSize = sTest.size();
对上面的测试内容进行如下分析:
在宽字节下,_tcslen()返回的值为 6,即每个字符(不分中英文)都占用一个存储单元(元素),即为 6 个存储单元。在宽字节下,1 个存储单元为 2 个字节,则该文本共占用了 12 个字节。
在多字节下,_tcslen()返回的值为 8,即每个英文占一个存储单元(元素),每个中文占两个存储单元,即为 8 个存储单元。在多字节下,1 存储单元为 1 个字节,则该文本共占用了 8 个字节。
CString 类型提供的GetLength()函数,也是返回的存储单元(元素)个数。
string和wstring类型,提供的length()和size()函数,这两个函数本质上是没有区别的。length()代替传统的 C 字符串,所以针对 C 中的_tcslen,给出相应的函数length();另一个身份是可以用作 STL 容器,所以按照 STL 容器的惯例给出size()。这两个函数都是返回的存储单元(元素)的个数。
3 宽字节字符与多字节字符的相互转换
3.1 MultiByteToWideChar 与 WideCharToMultiByte
(1) MultiByteToWideChar() 5
MultiByteToWideChar是一个 Windows API 函数,用于将多字节字符转换为宽字符。它的函数原型如下:
1
2
3
4
5
6
7
8
int MultiByteToWideChar(
UINT CodePage, // 源字符串的代码页,常见的值包括CP_UTF8、CP_ACP等。
DWORD dwFlags, // 转换标志,默认值为0。
LPCSTR lpMultiByteStr, // 源字符串
int cbMultiByte, // 源字符串的字节数
LPWSTR lpWideCharStr, // 目标缓冲区,用于接收转换后的宽字符。
int cchWideChar // 目标缓冲区的字符数
);
函数返回值为转换后的宽字符数,如果转换失败则返回 0。
使用MultiByteToWideChar函数可以将多字节字符串(如 UTF-8 编码的字符串)转换为宽字符字符串(如 UTF-16 编码的字符串)。可以通过指定不同的代码页来支持不同的字符集编码转换。
下方是一个利用该函数将多字节字符串转为宽字节字符串的函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
// 函数功能:将多字节编码的字符串转为宽字节
// 当需要转换utf8时,只需把函数中的CP_ACP替换为CP_UTF8
// szC(输入):需要转换的ANSI编码(或utf8编码)的字符串
// szW(输出):转换完的utf16编码的字符串
// szWlen(输入/输出):输入为szW在外部申请的数组长度,输出为字符串实际的长度
void Char2Wchar(const char* szC, wchar_t* szW, int& szWlen)
{
if (szC == nullptr || szW == nullptr) { assert(false); return; }
// -1表示“处理到字串尾”。后面两个参数表示“先不要复制,看看需要多少宽字节”
int iLength = MultiByteToWideChar(CP_ACP, 0, szC, -1, NULL, 0);
if (iLength == 0) { assert(false); return; } // 检错
wchar_t* wzsTemp = new wchar_t[iLength + 1]{ L'\0' };
iLength = MultiByteToWideChar(CP_ACP, 0, szC, -1, wzsTemp, iLength);
if (iLength == 0) { assert(false); return; } // 检错
if(iLength > szWlen) { assert(false);}
// 拷贝赋值:
wcscpy_s(szW, min(iLength + 1, szWlen), wzsTemp);
szWlen = iLength + 1;
delete[] wzsTemp;
}
(2) WideCharToMultiByte()
WideCharToMultiByte函数是一个 Windows API 函数,用于将宽字符转换为多字节字符。它的原型如下:
1
2
3
4
5
6
7
8
9
10
int WideCharToMultiByte(
UINT CodePage, // 指定要使用的字符编码方式
DWORD dwFlags, // 指定转换的行为选项,如是否使用默认字符、是否忽略无效字符等
LPCWSTR lpWideCharStr, // 指向要转换的宽字符字符串。
int cchWideChar, // 指定要转换的宽字符的数量,若为-1,则表示字符串以NULL结尾
LPSTR lpMultiByteStr, // 指向接收转换后的多字节字符的缓冲区。
int cbMultiByte, // 指定接收缓冲区的大小。
LPCSTR lpDefaultChar, // 指向用于替换无法转换的宽字符的默认字符。
LPBOOL lpUsedDefaultChar // 指向一个BOOL变量,用于指示是否使用了默认字符。
);
WideCharToMultiByte``函数的返回值表示转换后的多字节字符的数量,如果转换失败,则返回0。
使用WideCharToMultiByte函数可以将宽字符转换为多字节字符,方便在 Windows 环境下处理不同编码方式的文本数据。
下方是一个利用该函数将宽字节字符串转为多字节字符串的函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
// 将宽字节编码的字符串转为多字节
// 当需要转换utf8时,只需把函数中的CP_ACP替换为CP_UTF8
// szW(输入):需要转换的utf16编码的字符串
// szC(输出):转换完的ANSI编码(或utf8编码)的字符串
// szClen(输入/输出):输入为szC在外部申请的数组长度,输出为字符串实际的长度
void WChar2Char(const wchar_t* szW, char* szC, int& szClen)
{
if (szC == nullptr || szW == nullptr) { assert(false); return; } // 检错
// -1表示“处理到字串尾”,第5、6两参数表示“先不要复制,看看需要多少宽字节”
int len = WideCharToMultiByte(CP_ACP, 0, szW, -1, NULL, 0, NULL, NULL);
if (len == 0) { assert(false); return; } // 检错
char* cszTemp = new char[len + 1]{ '\0' };
len = WideCharToMultiByte(CP_ACP, 0, szW, -1, cszTemp, len, NULL, NULL);
if (len == 0) { assert(false); return; } // 检错
if (len > szClen) { assert(false); }
// 拷贝赋值:
strcpy_s(szC, min(len + 1, szClen), cszTemp);
szClen = len + 1;
delete[] cszTemp;
}
(3) 代码页
上述两个函数中的第一个参数均为CP_ACP,表示使用当前系统的默认代码页,对我们而言,即为将 UTF-16 编码转为 GBK 编码或从 GBK 编码转为 UTF-16 编码。
还有一个常用的宏定义为 CP_UTF8,即将 UTF-16 编码的宽字节字符串转换为 UTF-8 编码的多字节字符串,或者将 UTF-8 编码的多字节字符串转换为 UTF-16 编码的字符串。
需要注意的是,上文中提到的 UTF-8 编码和 UTF-16 编码都属于 Unicode 字符集的编码形式。
3.2 A2W、W2A、A2T、T2A
(1)使用方法
微软也建议使用这些宏作为字符串转换的方法。6
以下是使用A2W和W2A范例:
1
2
3
4
5
6
USES_CONVERSION;
char cTest[256] = "test测试";
wchar_t* cWTest = A2W(cTest);
USES_CONVERSION;
wchar_t cWTest[256] = L"test测试";
char* cTest = W2A(cWTest);
至于A2T、T2A、W2T、T2W这四个宏定义,在atlconv.h中是这样定义的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
#if defined(_UNICODE)
#define T2A W2A
#define A2T A2W
_Ret_z_ inline LPWSTR T2W(_In_z_ LPTSTR lp)
{
return lp;
}
_Ret_z_ inline LPTSTR W2T(_In_z_ LPWSTR lp)
{
return lp;
}
#else // !defined(_UNICODE)
#define T2W A2W
#define W2T W2A
_Ret_z_ inline LPSTR T2A(_In_z_ LPTSTR lp)
{
return lp;
}
_Ret_z_ inline LPTSTR A2T(_In_z_ LPSTR lp)
{
return lp;
}
#endif // defined(_UNICODE)
根据上面的定义,就是根据当前项目是否定义了_UNICODE这个宏来判断怎样转换A2T、T2A、W2T、T2W这四个宏。那么使用方法就与A2W和W2A相同了。
(2)USES_CONVERSION 宏
在使用这几个宏之前,均需要先调用USES_CONVERSION宏。
USES_CONVERSION是 ATL 中的一个宏定义。用于编码转换(用的比较多的是CString向LPCWSTR转换)。通俗的说,就是你用了这个宏后,就可以用一系列的字符串转换宏,不加USES_CONVERSION在使用A2W会出错。7
(3)栈溢出导致崩溃的问题
这是一个在使用上述宏时常见的问题。
问题就在于,这几个转换宏分配的内存是通过alloca在函数的栈中分配的。而 VC 编译器默认的栈内存空间是 2M。当在一个函数中循环调用它时就会不断的分配栈中的内存。占用满之后就会导致栈溢出,见参考文档8,另外史工在 20220825 的结构内训中也做了对应的解释。
3.3 CString
CString 用于转换可真是太方便了。
首先,CString 定义的字符串可以直接通过char*或wchar_t*来赋值,CString 的构造函数内部会根据类型进行自动转换。
例如在使用 Unicode 字符集的项目中,以下代码仍然是正常运行并且正确的:
1
2
char cTest[256] = "test中文ANSI编码";
CString strTest(cTest);
关于上述代码,史工在 20220825 的结构内训中进行了详细的解释,在录屏一小时左右的时刻。
另外,CStringA 与 CStringW 之间也仅需要一个 “=” 就可以完成转换,非常方便。
4 通过命令行调用 exe
4.1 在代码中调用 exe 并传入参数
调用 exe 的代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
SHELLEXECUTEINFO sei;
ZeroMemory(&sei, sizeof(SHELLEXECUTEINFO));
sei.cbSize = sizeof(SHELLEXECUTEINFO);
sei.hwnd = NULL;
sei.lpFile = cThisExePath; // cThisExePath是exe的路径,在上面已经攒好了
sei.lpVerb = _T("open");
sei.nShow = SW_SHOWNORMAL;
sei.fMask = SEE_MASK_DEFAULT;
sei.lpParameters = arguments; // arguments是传入的命令,在上面已经攒好了
if (ShellExecuteEx(&sei)) // 在这里调用exe
{ // 执行成功
WaitForSingleObject(sei.hProcess, INFINITE);
CloseHandle(sei.hProcess);
}
else
{ // 执行失败
DWORD error = GetLastError();
}
上面代码中的SHELLEXECUTEINFO在shellapi.h中是这样定义的:
1
2
3
4
5
6
7
#ifdef UNICODE
typedef SHELLEXECUTEINFOW SHELLEXECUTEINFO;
typedef LPSHELLEXECUTEINFOW LPSHELLEXECUTEINFO;
#else
typedef SHELLEXECUTEINFOA SHELLEXECUTEINFO;
typedef LPSHELLEXECUTEINFOA LPSHELLEXECUTEINFO;
#endif // UNICODE
看上面的定义,该类型的定义与字符集相关,UNICODE 字符集下,对应SHELLEXECUTEINFOW类型,在该类型下,其内的所有字符串均对应LPCWSTR;在采用多字节的情况下,对应的则为SHELLEXECUTEINFOA,在该类型下的所有字符串对应的均为LPCSTR。
4.2 在 exe 中对命令进行解析
通过重写CCommandLineInfo类中的ParseParam()函数对命令进行提取:
1
2
3
4
5
6
7
8
9
10
11
12
13
class CMyCmdLineInfo : public CCommandLineInfo
{
public:
virtual void ParseParam(const TCHAR* pszParam, BOOL bFlag, BOOL bLast);
};
void CMyCmdLineInfo ::ParseParam(const TCHAR* pszParam, BOOL bFlag, BOOL bLast)
{
// 记录命令:
CString g_StrCmd = pszParam;
// 返回基类:
CCommandLineInfo::ParseParam(pszParam, bFlag, bLast);
}
在项目中的InitInstance()函数中采用以下方式调用即可:
1
2
CMyCommandLineInfo cmdInfo;
ParseCommandLine(cmdInfo);
函数ParseCommandLine是基类CWinApp中提供的函数,在appcore.cpp中的源码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
void CWinApp::ParseCommandLine(CCommandLineInfo& rCmdInfo)
{
for (int i = 1; i < __argc; i++)
{
LPCTSTR pszParam = __targv[i];
BOOL bFlag = FALSE;
BOOL bLast = ((i + 1) == __argc);
if (pszParam[0] == '-' || pszParam[0] == '/')
{
// remove flag specifier
bFlag = TRUE;
++pszParam;
}
rCmdInfo.ParseParam(pszParam, bFlag, bLast);
}
}
可以发现,其还是通过__targv指针来获取的命令行,__targv是一个宏定义,在tcahr.h中有如下定义:
1
2
3
4
5
#ifdef _UNICODE
#define __targv __wargv
#else /* _UNICODE */
#define __targv __argv
#endif
在stdlib.h中:
1
2
3
4
5
6
7
8
9
10
11
12
13
_ACRTIMP int* __cdecl __p___argc (void);
_ACRTIMP char*** __cdecl __p___argv (void);
_ACRTIMP wchar_t*** __cdecl __p___wargv(void);
#ifdef _CRT_DECLARE_GLOBAL_VARIABLES_DIRECTLY
extern int __argc;
extern char** __argv;
extern wchar_t** __wargv;
#else
#define __argc (*__p___argc()) // Pointer to number of command line arguments
#define __argv (*__p___argv()) // Pointer to table of narrow command line arguments
#define __wargv (*__p___wargv()) // Pointer to table of wide command line arguments
#endif
可以发现,__targv是与字符集相关的,会根据是否为 UNICODE 字符集而对应于wchar_t的指针或是char的指针。
4.3 测试不同字符集下调用exe
测试项目为 DailyTipHsb,该解决方案中有两个项目,一个是目标 exe,一个是控制台程序,负责测试调用 exe。这两个项目都适配了 UNICODE 与 MBCS 两种字符集。
经测试,无论传入的命令字符串编码是 UNICODE 或 MBCS、无论 exe 本身是 UNICODE 还是 MBCS,exe 中都能正确接收到命令。
很神奇,但是不知道为什么。
猜测是操作系统在接收到命令行以后,会先将字符串转为系统对应的字符,在 Windows 下也就是 UTF16,然后再调用 exe 时,又会将字符串转为 exe 所需的字符集。
一些遗留的问题
-
CString做接口函数的传参可能会有什么问题?
-
如果用TCHAR类型做接口的参数类型会怎么样
-
总结CString、string、LPTSRT、char等各种类型的字符串相互转换的方法
-
总结int、float等类型转为字符串的方法
-
怎样利用iconv实现转换字符串编码?
-
参考文章9
-
对于CString类型,MFC提供的和STL提供的有啥不一样?
-
这俩文件是干啥的:
<stlstr.h><afxstr.h>?
参考文献
-
Microsoft文档. tchar.h 中的一般文本映射[DB/OL]. (2023-06-16). ↩︎ ↩︎2 ↩︎3 ↩︎4
-
CSDN. string,wstring,cout,wcout 与中文字符的输入输出[DB/OL]. (2022-06-05). ↩︎ ↩︎2
-
Microsoft文档. MultiByteToWideChar函数(stringapiset.h) [DB/OL]. (2023-08-26). ↩︎
-
Microsoft文档. TN059:使用MFC MBCS/Unicode转换宏[DB/OL]. (2023-06-16). ↩︎
-
CSDN. A2W、W2A等转换函数,由于使用的比较平繁,所以程序内存一直上涨,导致崩溃[DB/OL]. (2016-06-06) ↩︎ ↩︎2
-
码农教程. Visual Studio使用多字节字符集与使用Unicode字符集[DB/OL]. (2022-11-08). ↩︎
-
BOOTWIKI. 带你玩转 Visual Studio——带你理解多字节编码与 Unicode 码[DB/OL]. (2022-11-08). ↩︎
-
开发者社区. Visual Studio——使用多字节字符集与使用Unicode字符集[DB/OL]. (2022-11-03). ↩︎
-
简书. SBCS、DBCS、ASCII、MBCS(ANSI)、Unicode [DB/OL]. (2020-02-11). ↩︎
-
个人图书馆. 在程序中正确使用 Unicode 和 MBCS 字符集 [DB/OL]. (2022-02-17). ↩︎