Oss Mongodb双跑压测
Oss Mongodb双跑压测
背景
为了将 OSS 服务从 Cassandra 改为 MongoDB,修改了上游 Store 服务的代码,将所有请求另外拷贝一份,异步双写到新的 OSS-Mongo 服务中。这样可以保证在不影响主线业务的情况下,逐步使 MongoDB 中的数据与 Cassandra 中数据一致。待 30 天数据到期后,MongoDB 与 Cassandra 中数据就会完全一致。
测试前(2024年10月12日15:00)的双跑布置现状(Store 与 OSS-Mongo 为 2:1 的比例双跑)如下图所示:

测试内容
压力测试 OSS-MongoDB 服务,观察延迟是否增加、带宽是否限制、连接数的变化。
内容:
- OSS-Mongo 服务接受目前所有 8 台 Store 服务的双跑请求时的压力表现;
- OSS-Mongo 服务停启后的瞬时压力表现;
- OSS-Mongo 接受 8 台 Store 服务的双跑请求 + 额外的写入请求时的压力表现;
- MongoDB 服务在上述测试内容下的压力表现。
测试步骤
- 第一阶段:分批将所有 Store(共8台)指向 10.30.20.246 上的 OSS-Mongo,也就是由 2:1 升到 8:1;
- 第二阶段:关停 10.30.20.246 上的 OSS-Mongo,此时所有 8 台 Store 的双跑发送消息会失败,并存储等待连接回复后进行消息恢复;
- 第三阶段:启动 10.30.20.246 上的 OSS-Mongo,此时所有 8 台 Store 会同时将刚刚囤积的“待恢复消息”同时发送给 10.30.20.246 上的 OSS-Mongo,OSS-Mongo 会在刚启动的一瞬间收到大量的请求;
- 第四阶段:本地用 py 脚本向 OSS-Mongo 循环发消息进行持续压力测试;
- 第五阶段:将 Store 配置恢复为压力测试之前。
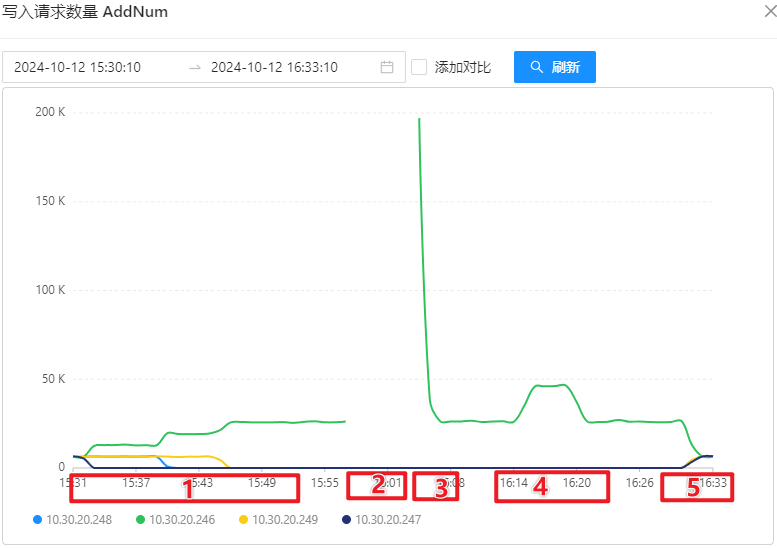
压测过程可以通过写入请求量体现,如下图所示:
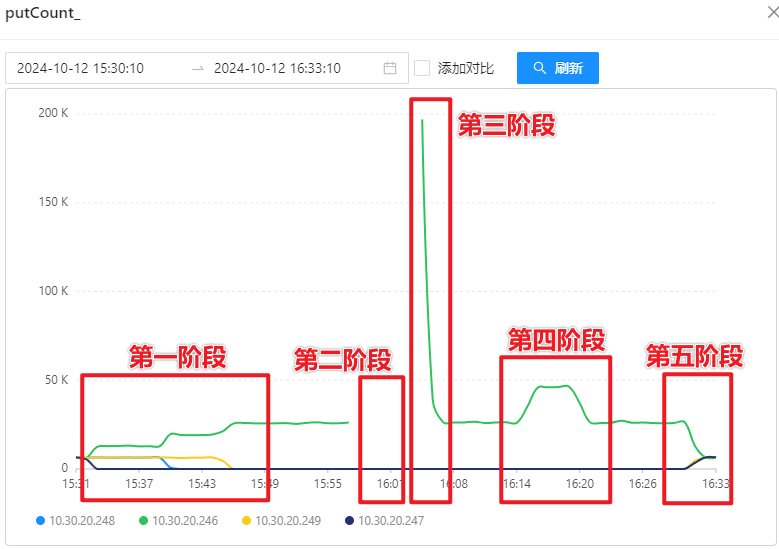
测试阶段的监控情况
OSS 服务监控
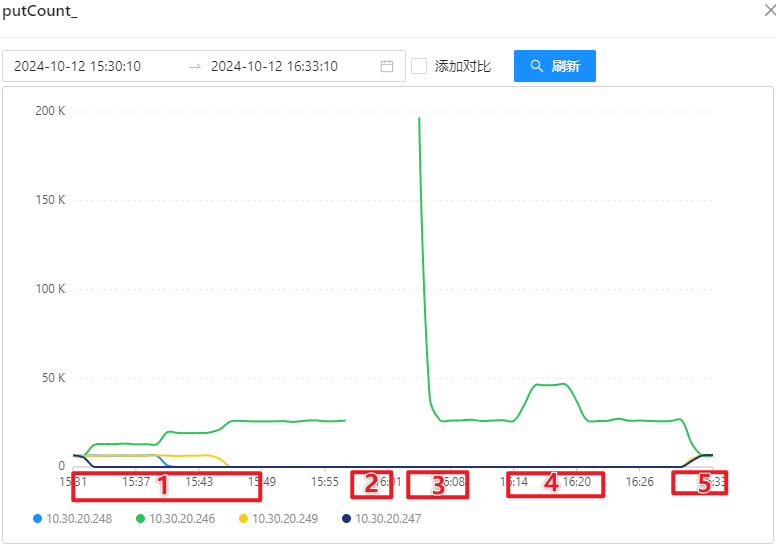
- OSS 写入请求量:
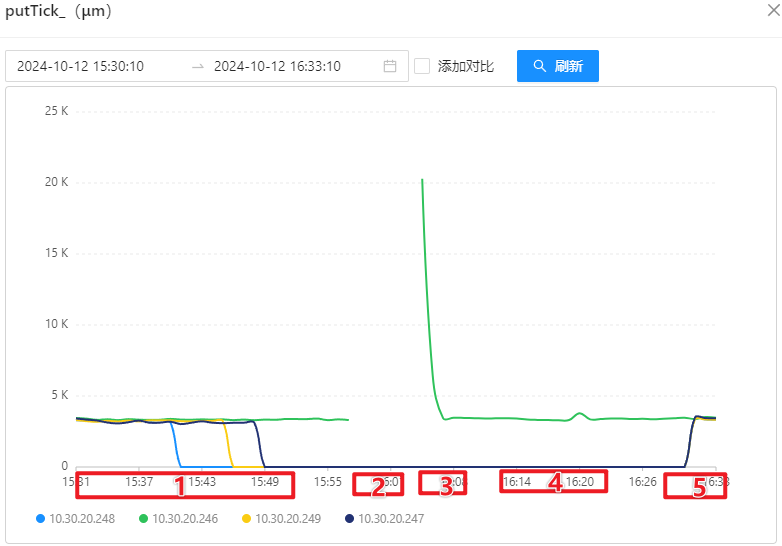
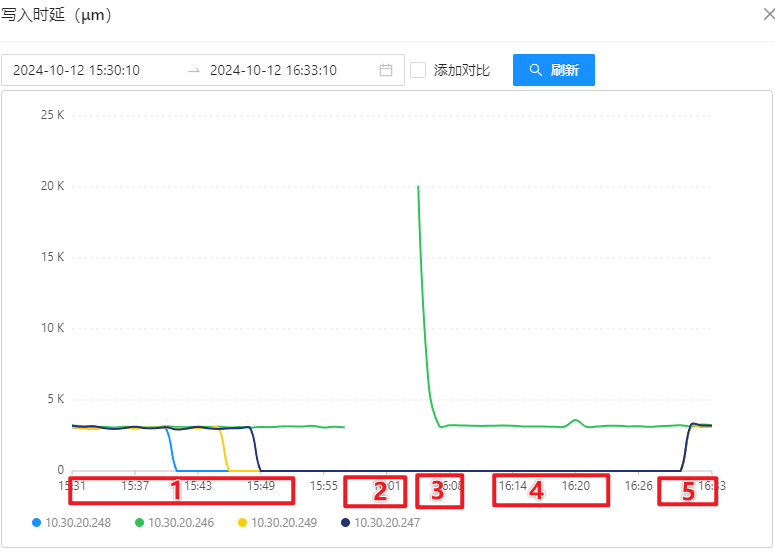
- OSS 写入延迟:
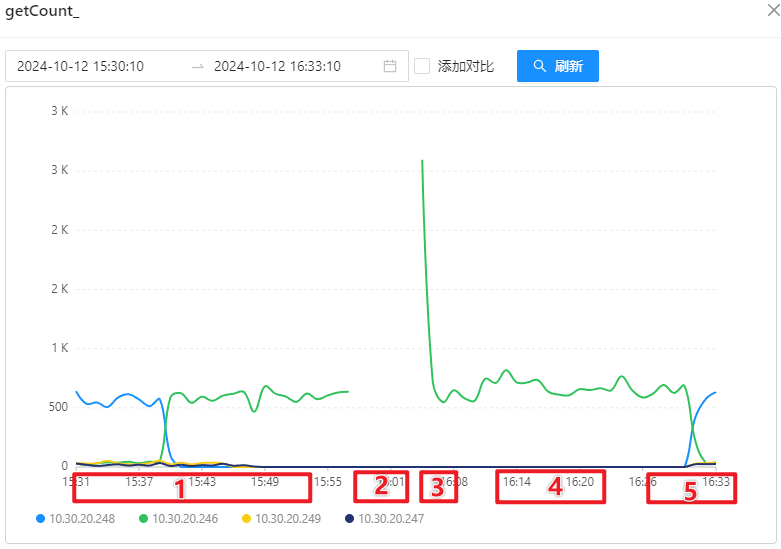
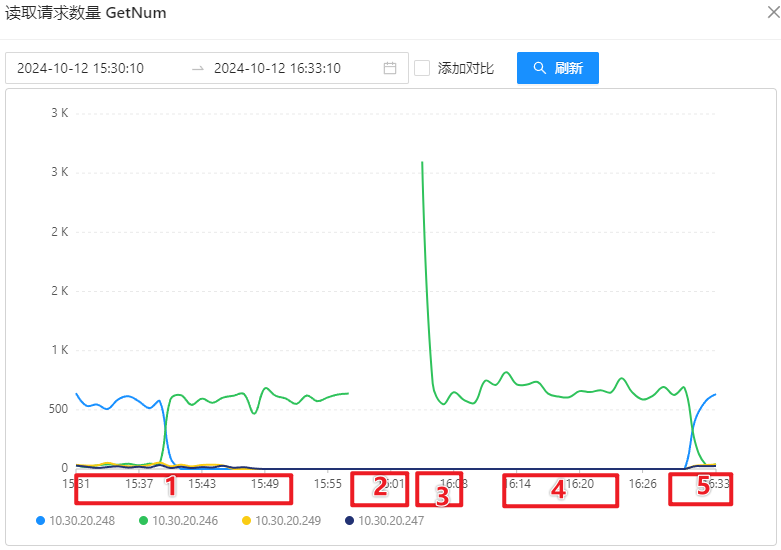
- 获取数量:
- 获取延迟:
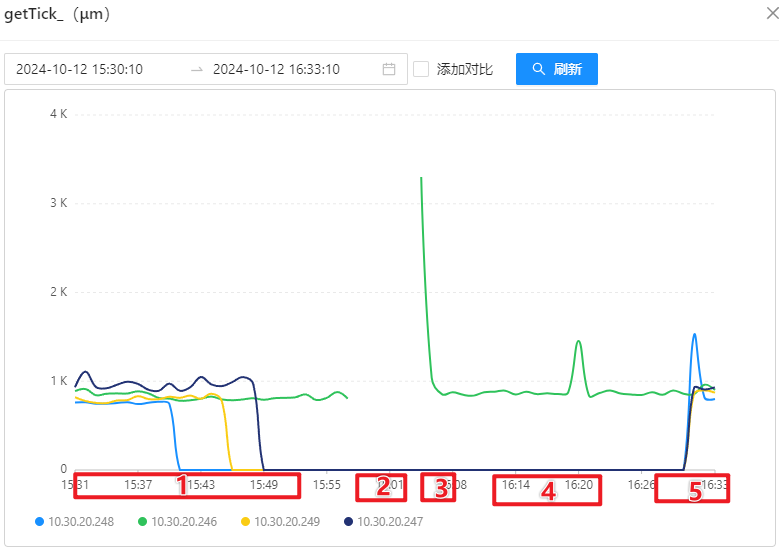
OSS-Mongo 监控
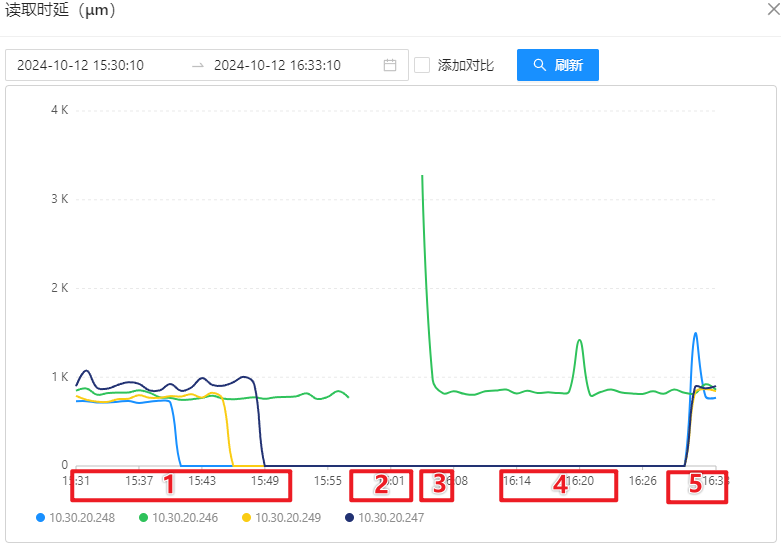
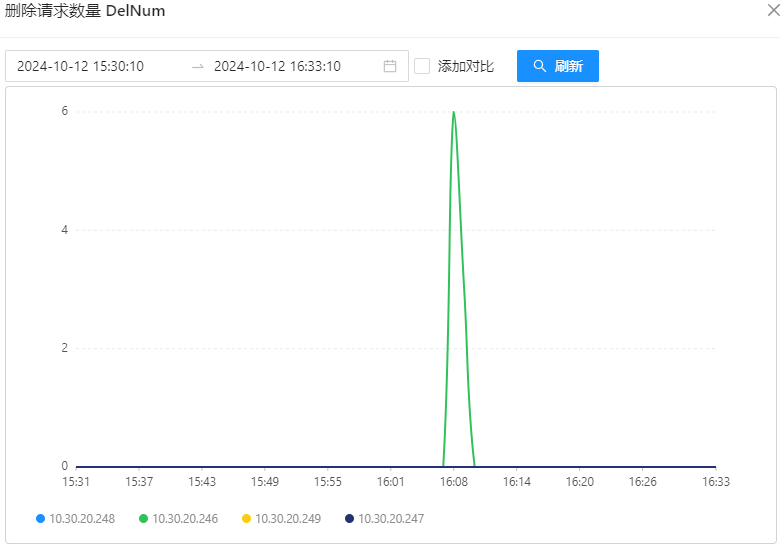
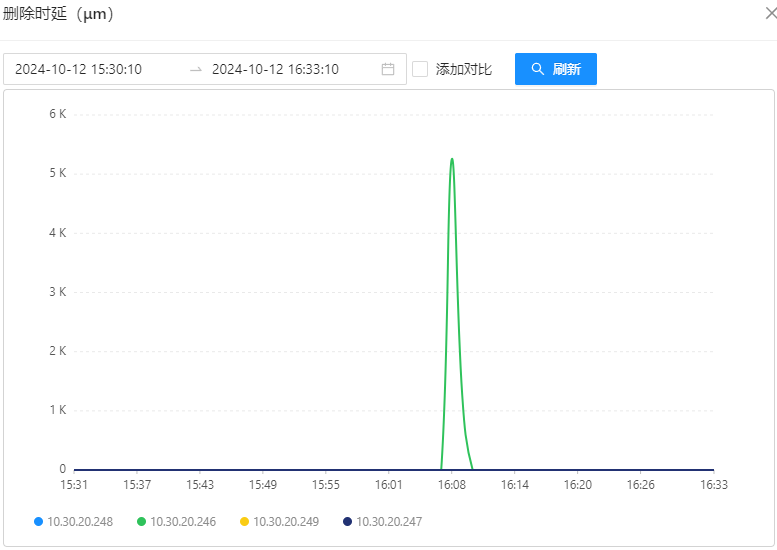
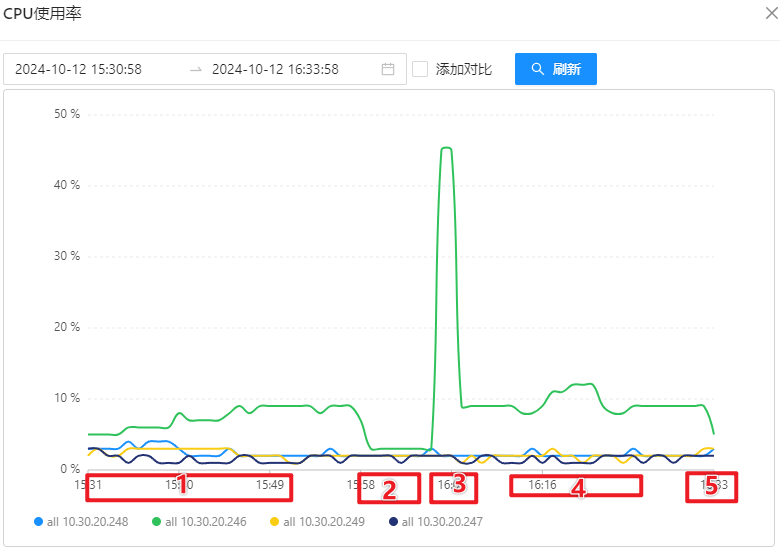
OSS 机器性能监控
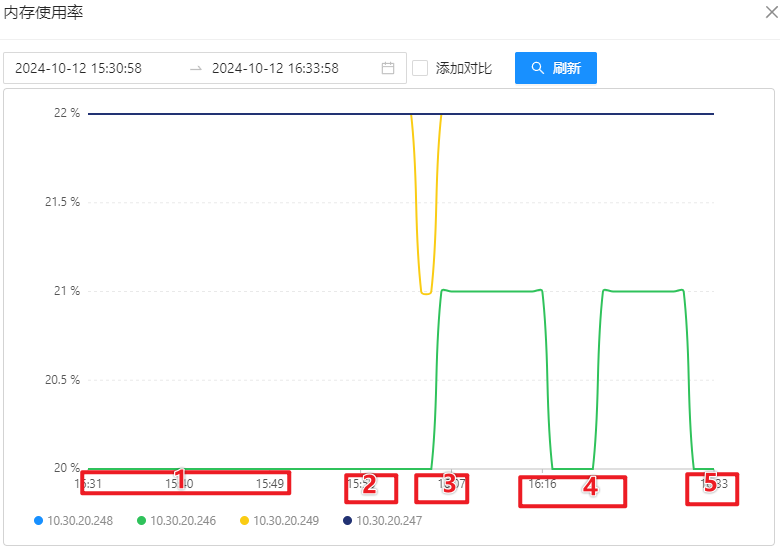
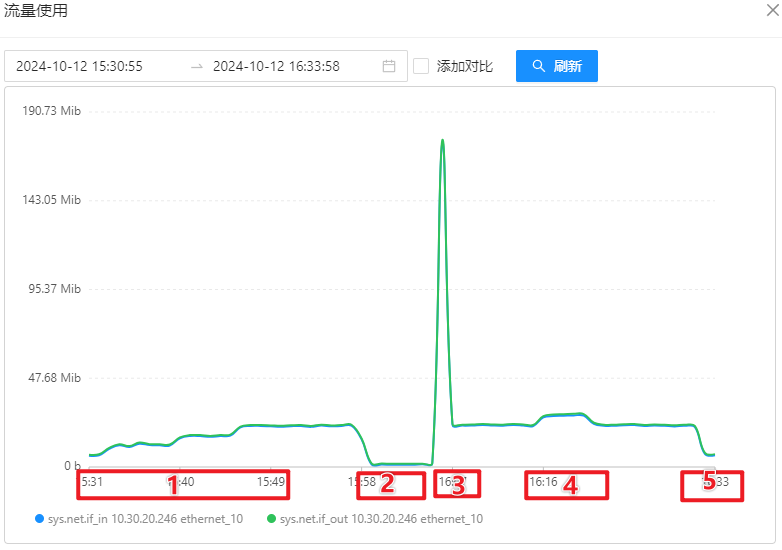
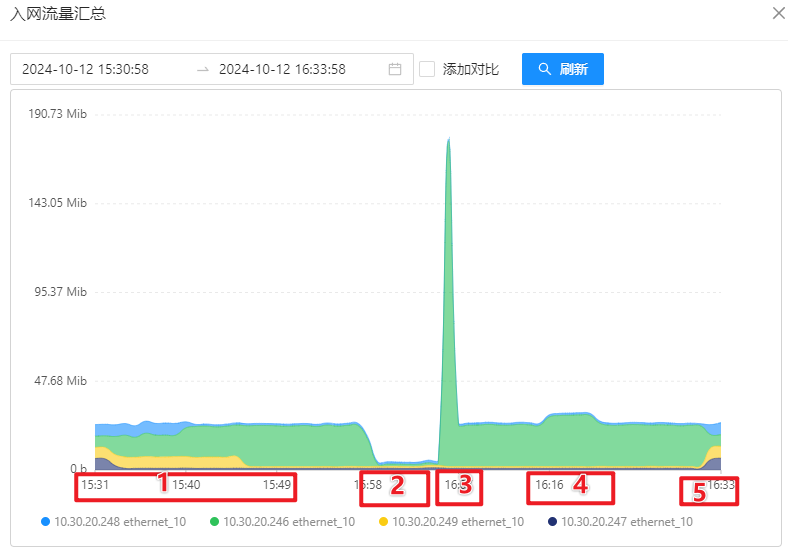
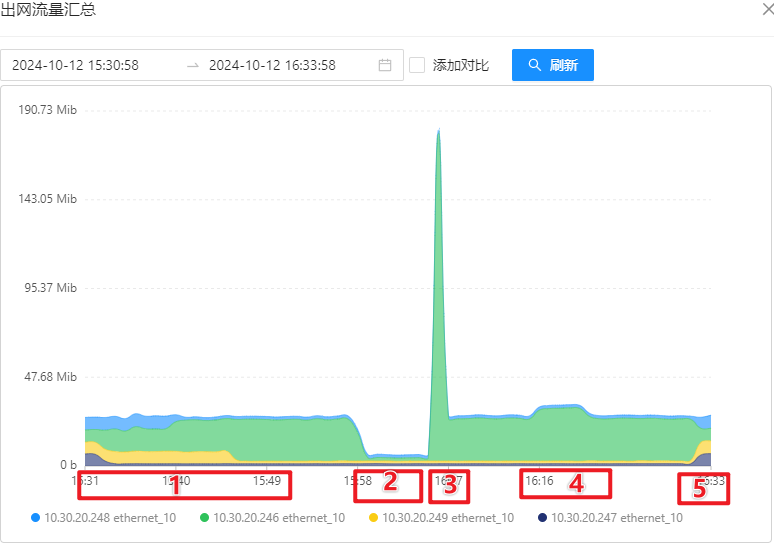
MongoDB 服务器监控
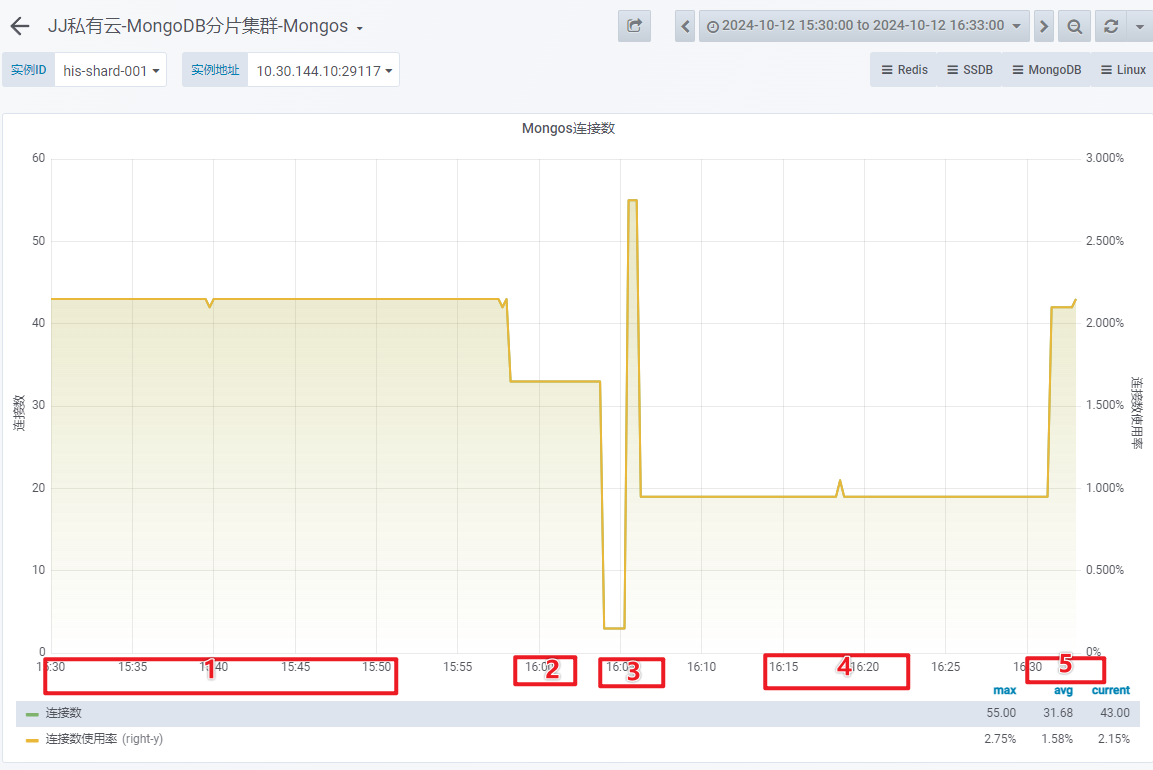
- Mongos 连接数
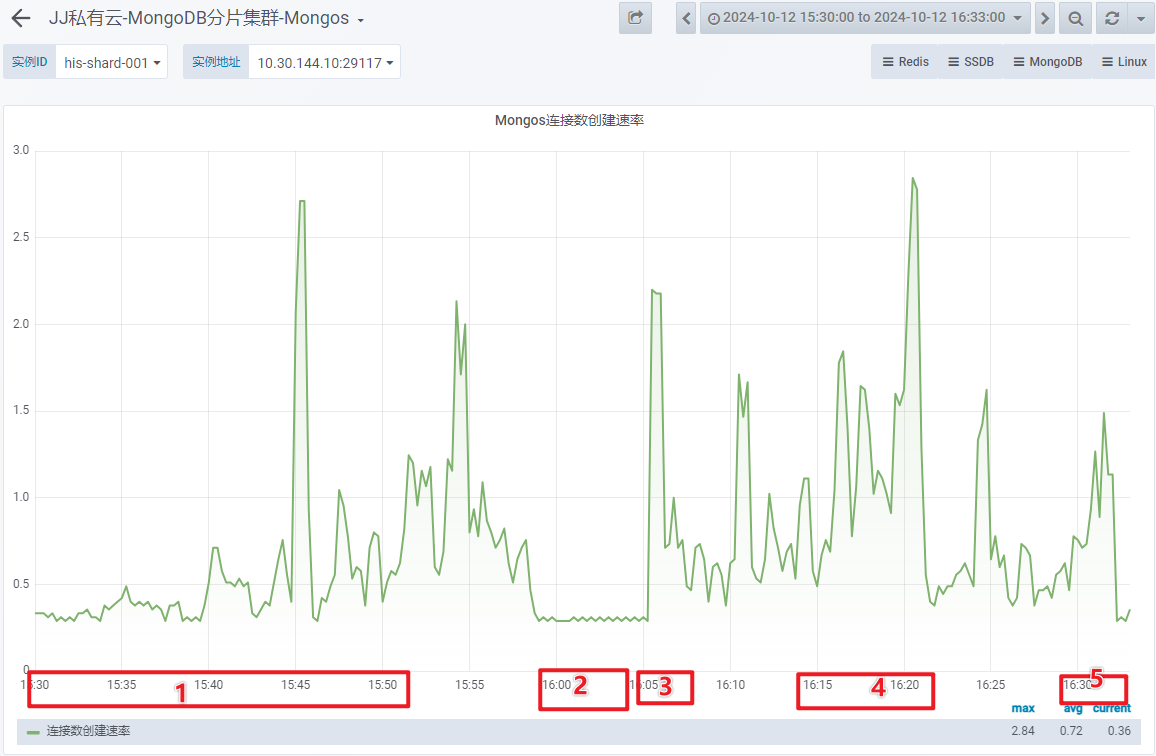
- Mongos 连接数创建速率
- Mongos 命令数量
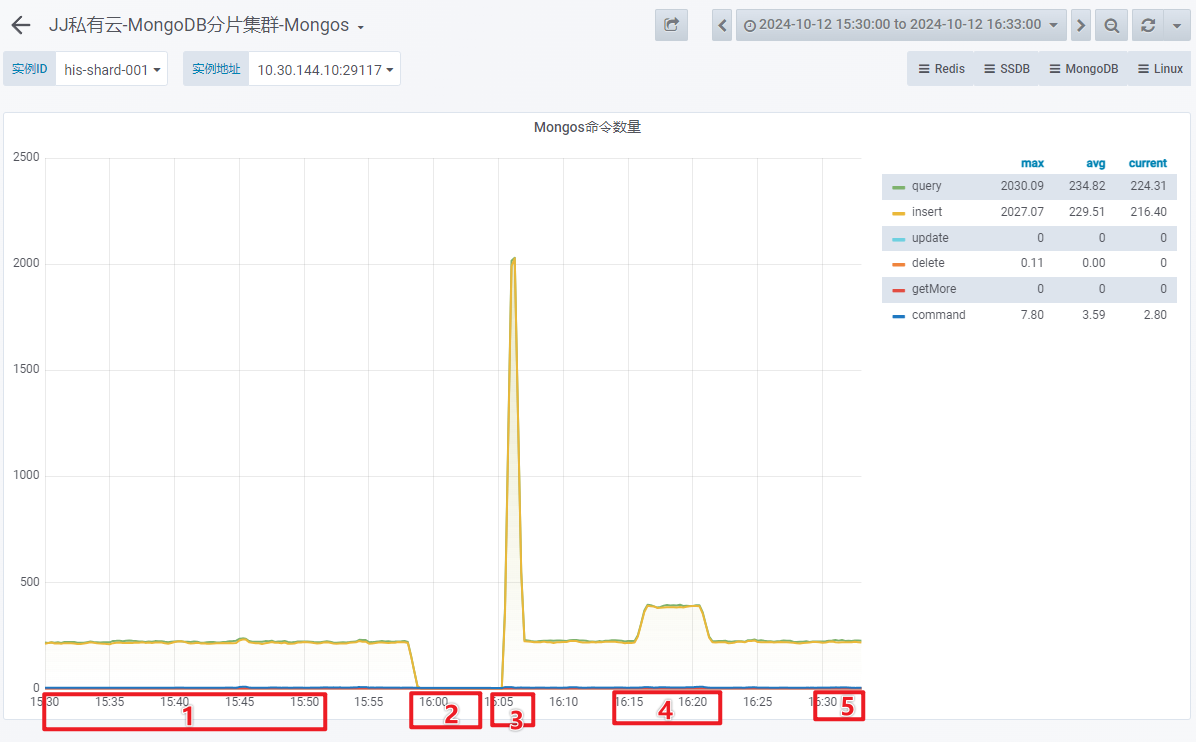
- Mongos 命令失败数量在上述时间段内均为 0。
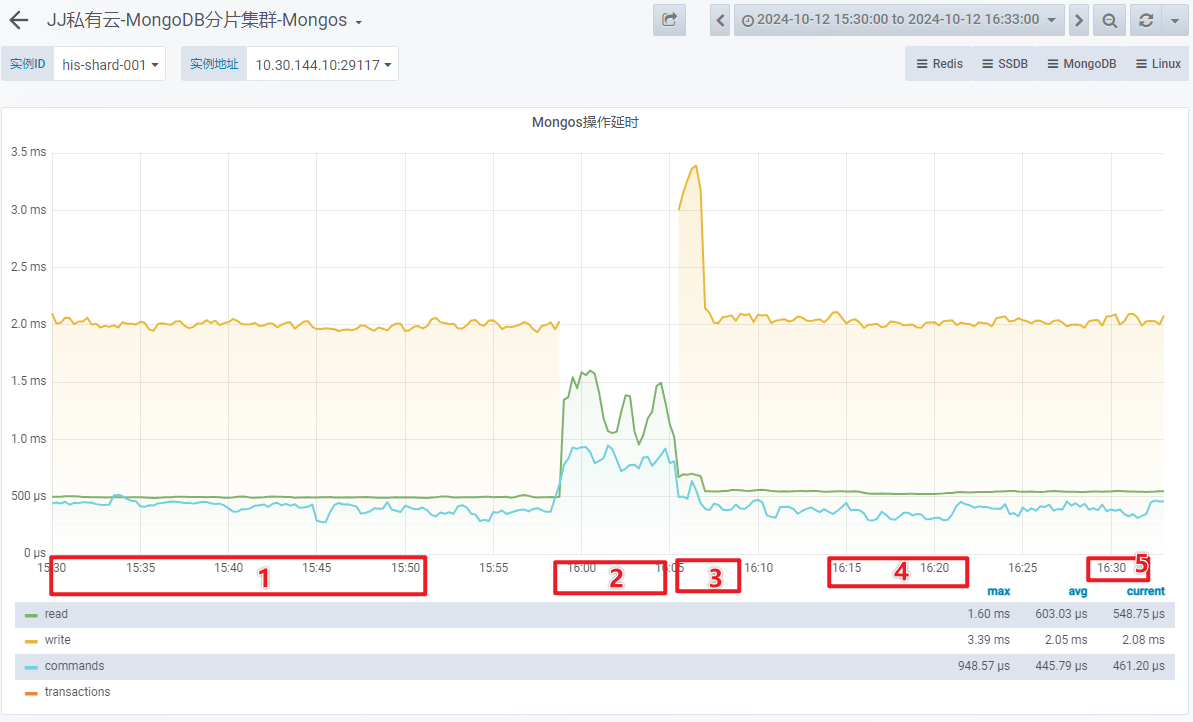
- Mongos 操作延时
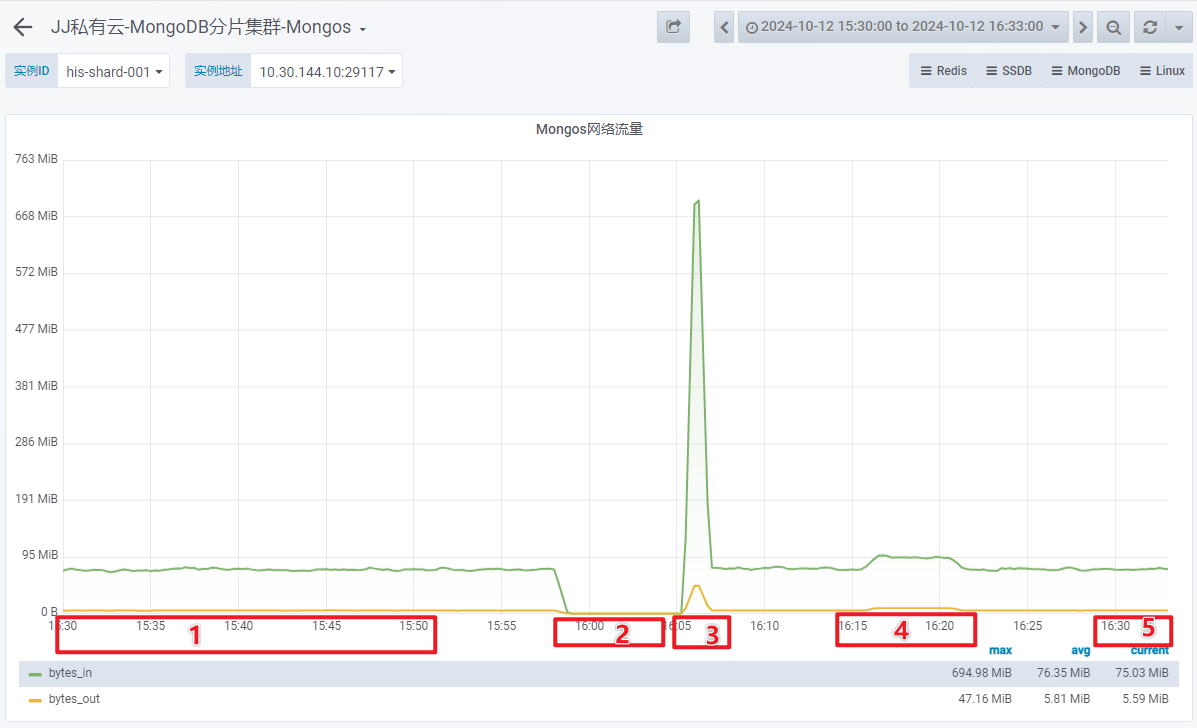
- Mongos 网络流量
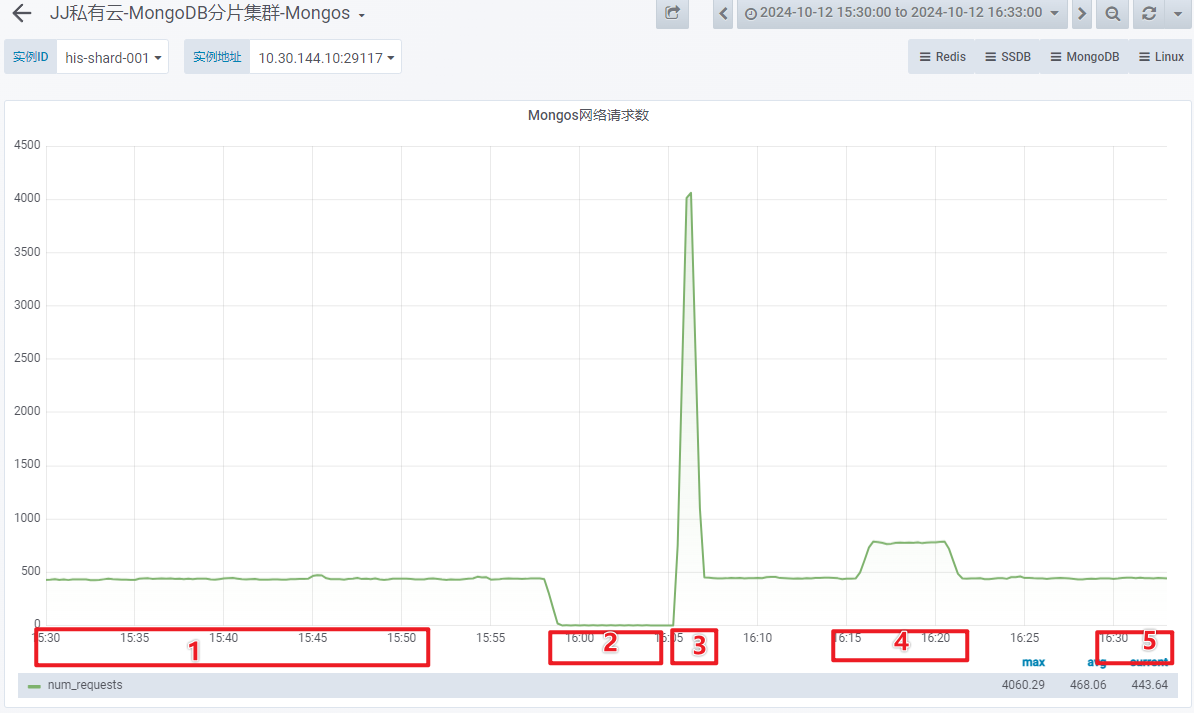
- 网络请求数:
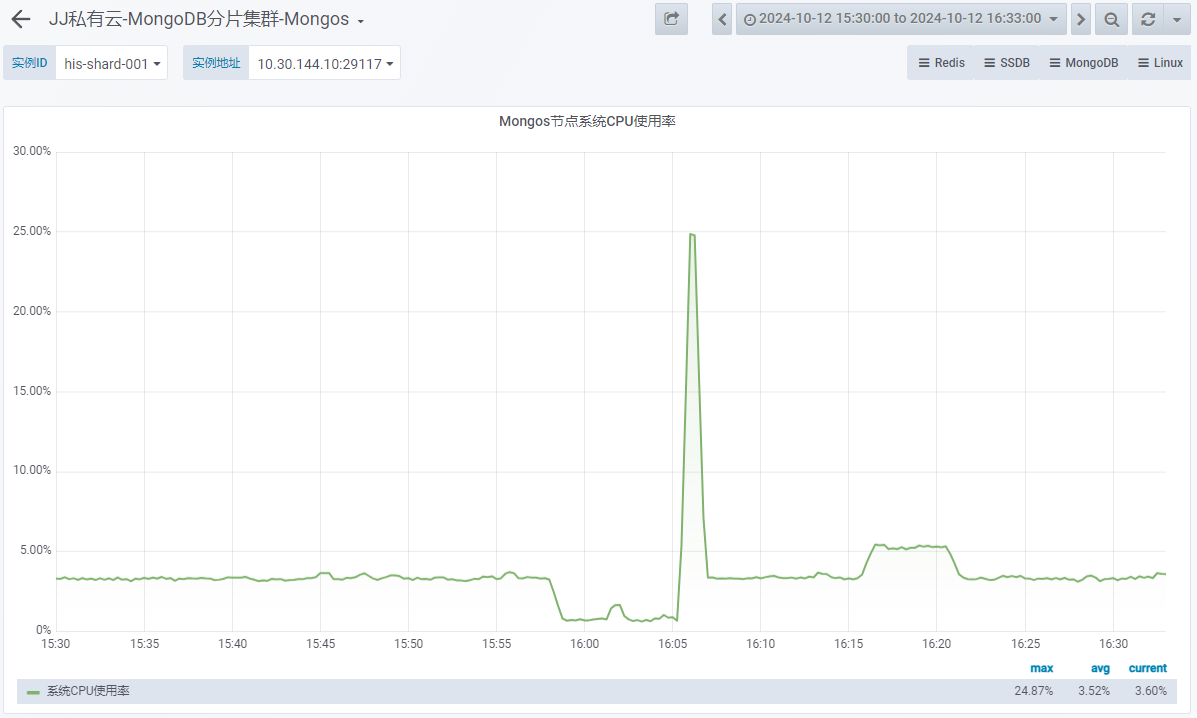
- Mongos 系统 CPU 使用率
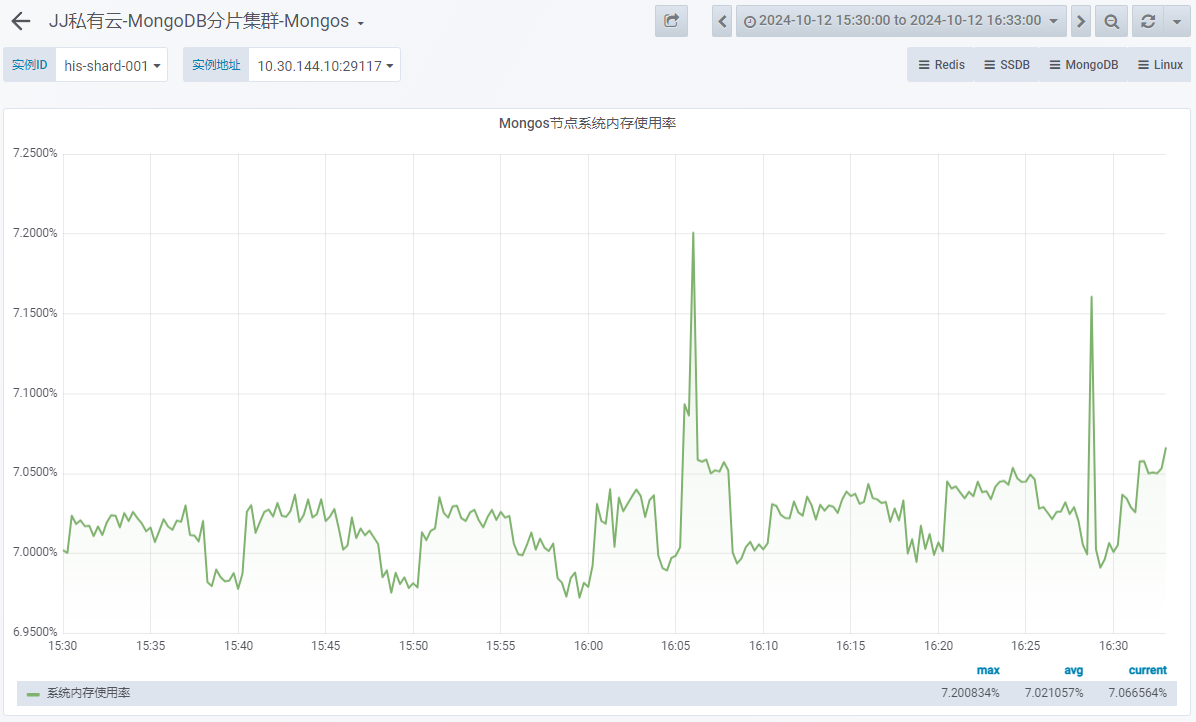
- Mongos 系统内存使用率
结论
-
1 台 OSS-Mongo 可以承受来自 8 台 Store 的双跑请求。此时,延迟不会增加、网络带宽没有跑满、CPU使用率仅为 9%。
-
1 台 OSS-Mongo 可以承受瞬时 20万/min 的请求量,此时,延迟会增加、网络带宽显著增加、CPU使用率瞬时上涨为 45%。
-
MongoDB 节点可以承受住瞬时 20万/min 的请求量,此时,延迟增加、网络带宽增加、CPU使用率瞬时上涨为 25%。
-
当进行 8:1 双跑时,OSS-Mongo 中的 MaxMongoPoolSize 会限制连接数,可能会导致性能瓶颈。
当多对 1 进行双跑时,可以考虑增大参数 MaxMongoPoolSize 。
本文由作者按照
CC BY 4.0
进行授权