Mongodb相关
[TOC]
MongoDB 介绍
SQL 与 MongoDB 常见术语对比
| mySQL | MongoDB |
|---|---|
| 数据库(Database) | 数据库(Database) |
| 表(Table) | 集合(Collection) |
| 行(Row) | 文档(Document) |
| 列(Col) | 字段(Field) |
| 主键(Primary Key) | 对象 ID(Objectid) |
| 索引(Index) | 索引(Index) |
| 嵌套表(Embeded Table) | 嵌入式文档(Embeded Document) |
| 数组(Array) | 数组(Array) |
文档
MongoDB 中的记录就是一个 BSON 文档,它是由键值对组成的数据结构,类似于 JSON 对象,是 MongoDB 中的基本数据单元。字段的值可能包括其他文档、数组和文档数组。1

文档的键是字符串。除了少数例外情况,键可以使用任意 UTF-8 字符。
- 键不能含有
\0(空字符)。这个字符用来表示键的结尾。 .和$有特别的意义,只有在特定环境下才能使用。- 以下划线
_开头的键是保留的(不是严格要求的)。
BSON [bee·sahn] 是 Binary JSON的简称,是 JSON 文档的二进制表示,支持将文档和数组嵌入到其他文档和数组中,还包含允许表示不属于 JSON 规范的数据类型的扩展。
根据维基百科对 BJSON 的介绍,BJSON 的遍历速度优于 JSON,这也是 MongoDB 选择 BSON 的主要原因,但 BJSON 需要更多的存储空间。
与 JSON 相比,BSON 着眼于提高存储和扫描效率。BSON 文档中的大型元素以长度字段为前缀以便于扫描。在某些情况下,由于长度前缀和显式数组索引的存在,BSON 使用的空间会多于 JSON。
集合
MongoDB 集合存在于数据库中,没有固定的结构,也就是 无模式 的,这意味着可以往同一个集合中插入不同格式和类型的数据。不过,通常情况下插入集合中的数据都会有一定的关联性。
集合不需要事先创建,当第一个文档插入或者第一个索引创建时,如果该集合不存在,则会创建一个新的集合。
集合名可以是满足下列条件的任意 UTF-8 字符串:
- 集合名不能是空字符串
""。 - 集合名不能含有
\0(空字符),这个字符表示集合名的结尾。 - 集合名不能以”system.”开头,这是为系统集合保留的前缀。例如
system.users这个集合保存着数据库的用户信息,system.namespaces集合保存着所有数据库集合的信息。 - 集合名必须以下划线或者字母符号开始,并且不能包含
$。
数据库
数据库用于存储所有集合,而集合又用于存储所有文档。一个 MongoDB 中可以创建多个数据库,每一个数据库都有自己的集合和权限。1
MongoDB 预留了几个特殊的数据库。
- admin : admin 数据库主要是保存 root 用户和角色。例如,system.users 表存储用户,system.roles 表存储角色。一般不建议用户直接操作这个数据库。将一个用户添加到这个数据库,且使它拥有 admin 库上的名为 dbAdminAnyDatabase 的角色权限,这个用户自动继承所有数据库的权限。一些特定的服务器端命令也只能从这个数据库运行,比如关闭服务器。
- local : local 数据库是不会被复制到其他分片的,因此可以用来存储本地单台服务器的任意 collection。一般不建议用户直接使用 local 库存储任何数据,也不建议进行 CRUD 操作,因为数据无法被正常备份与恢复。
- config : 当 MongoDB 使用分片设置时,config 数据库可用来保存分片的相关信息。
- test : 默认创建的测试库,连接 mongod 服务时,如果不指定连接的具体数据库,默认就会连接到 test 数据库。
数据库名可以是满足以下条件的任意 UTF-8 字符串:
- 不能是空字符串
""。 - 不得含有
' '(空格)、.、$、/、\和\0(空字符)。 - 应全部小写。
- 最多 64 字节。
数据库名最终会变成文件系统里的文件,这也就是有如此多限制的原因。
MongoDB 集群
副本集群
MongoDB 的复制集群又称为副本集群,是一组维护相同数据集合的 mongod 进程。1
客户端连接到整个 Mongodb 复制集群,主节点机负责整个复制集群的写,从节点可以进行读操作,但默认还是主节点负责整个复制集群的读。主节点发生故障时,自动从从节点中选举出一个新的主节点,确保集群的正常使用,这对于客户端来说是无感知的。
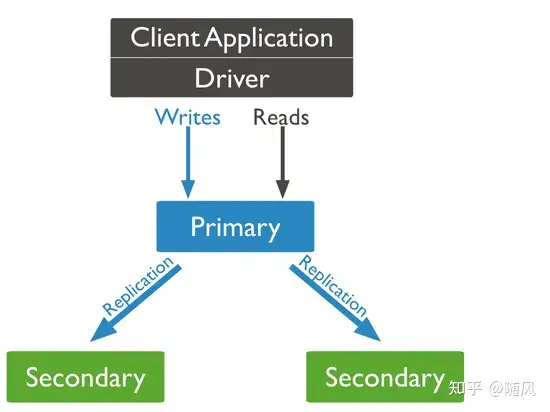
通常来说,一个复制集群包含 1 个主节点(Primary),多个从节点(Secondary)以及零个或 1 个仲裁节点(Arbiter)。
- 主节点 :整个集群的写操作入口,接收所有的写操作,并将集合所有的变化记录到操作日志中,即 oplog。主节点挂掉之后会自动选出新的主节点。
- 从节点 :从主节点同步数据,在主节点挂掉之后选举新节点。不过,从节点可以配置成 0 优先级,阻止它在选举中成为主节点。
- 仲裁节点 :这个是为了节约资源或者多机房容灾用,只负责主节点选举时投票不存数据,保证能有节点获得多数赞成票。
下图是一个典型的三成员副本集群:
主节点与备节点之间是通过 oplog(操作日志) 来同步数据的。oplog 是 local 库下的一个特殊的 上限集合(Capped Collection) ,用来保存写操作所产生的增量日志,类似于 MySQL 中 的 Binlog。
上限集合类似于定长的循环队列,数据顺序追加到集合的尾部,当集合空间达到上限时,它会覆盖集合中最旧的文档。上限集合的数据将会被顺序写入到磁盘的固定空间内,所以,I/O 速度非常快,如果不建立索引,性能更好。
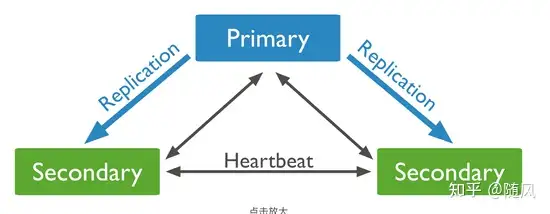
当主节点上的一个写操作完成后,会向 oplog 集合写入一条对应的日志,而从节点则通过这个 oplog 不断拉取到新的日志,在本地进行回放以达到数据同步的目的。
副本集最多有一个主节点。如果当前主节点不可用,一个选举会抉择出新的主节点。MongoDB 的节点选举规则能够保证在 Primary 挂掉之后选取的新节点一定是集群中数据最全的一个。
分片集群
分片集群是 MongoDB 的分布式版本,相较副本集,分片集群数据被均衡的分布在不同分片中, 不仅大幅提升了整个集群的数据容量上限,也将读写的压力分散到不同分片,以解决副本集性能瓶颈的难题。
具体详见参考1
MongoDB 的连接
SRV 连接字符串
什么是 SRV
MongoDB中的SRV连接是指使用DNS SRV记录(Service Record)来连接MongoDB数据库的方法。这种连接方式提供了更灵活和可靠的数据库连接机制。以下是关于SRV连接的一些重要点:
- DNS SRV记录: SRV记录是DNS中的一种资源记录,用于定义某个服务的位置(如主机名和端口号)。
- 自动发现: 使用SRV连接,客户端可以自动发现MongoDB集群中的所有可用服务器,而不需要手动指定每个服务器的地址和端口。
- 连接字符串格式: SRV连接字符串通常以”mongodb+srv://”开头,而不是标准的”mongodb://”。
- 负载均衡: SRV记录可以包含多个服务器地址,允许客户端实现简单的负载均衡。
- 简化配置: 只需要记住一个域名,而不是多个服务器地址,简化了配置过程。
- 动态更新: 可以通过更新DNS记录来改变集群配置,而不需要修改应用程序代码。
- 安全性: SRV记录可以与TLS/SSL结合使用,提供更安全的连接。
SRV 连接方法
详见参考2。
公司提供的 MongoDB 数据库连接方式(适用于副本集和分片集群)[^来自邮件]
1)连接说明
SRV连接串URI格式如下:
1
mongodb+srv://[username:password@]host[/[defaultauthdb][?options]]
其中host对应主机地址,options中需要使用srvServiceName指定服务名
2)mongosh 命令行连接示例
以官方mongosh命令行客户端的方式为例:
1
mongosh "mongodb+srv://**{username\**}:{\******password}@**service.**jjdev**.local/admin?tls=false&srvServiceName=**devxwsjz-001-mongodb**" --apiVersion 1
备注1:采用上述方式连接数据库,应用程序可以避免因数据库运维操作而修改连接地址,也可以适应数据库的自动节点发现、角色识别和故障切换等机制,简化应用程序的设计和维护
备注2:使用SRV连接串时默认开启TLS,因此需要显示禁用,需要使用连接选项tls=false
备注3:apiVersion参数是mongosh工具的Stable API 启用方法
标准连接字符串
1)独立运行的实例
以下独立运行的实例连接字符串实施访问控制:
1
mongodb://myDatabaseUser:D1fficultP%40ssw0rd@mongodb0.example.com:27017/?authSource=admin
以我自己的Linux服务器为例,连接admin数据库:
1
mongosh mongodb://myRoot:passw0rd@59.110.31.194:27017/admin
也可以使用ssh加密连接:
1
mongodb://myRoot:passw0rd@59.110.31.194:27017/?authSource=admin&ssl=true
上面的账户密码对应的是服务器上MongoDB中的账户密码,在MongoDB中创建一个账户密码:
1
2
3
4
5
6
7
8
9
10
11
12
//创建一个超级用户,拥有所有数据库的所有权限:
db.createUser({user:"myRoot",pwd:"passw0rd",roles: ['root']})
// 修改密码:
db.updateUser("root",{pwd:"K@************"});
//role 代表可以进行的操作,这里是读写,db是指针对哪个数据库,这里创建的这个用户对于testDB拥有读写权限创建用户
db.createUser({user:'test',pwd:'test',roles:[{role:'readWrite',db:'testDB'}]})
//这是创建一个超级用户,拥有所有数据库的所有权限
db.createUser({user: 'root', pwd: '123456', roles: ['root']})
//更新用户
db.updateUser(用户名,{user:'test',pwd:'admin',roles:[{role:'read',db:'testDB'}]})
//删除用户
db.dropUser('test')
2)分片集群
以下分片集群连接字符串包含这些元素:
1
mongodb://myDatabaseUser:D1fficultP%40ssw0rd@mongos0.example.com:27017,mongos1.example.com:27017,mongos2.example.com:27017/?authSource=admin
3)副本集
以下副本集连接字符串包含这些元素:
replicaSet选项- 副本集配置中列出的
mongod实例的主机名 - 用于实施访问控制的用户名和密码:
1
mongodb://myDatabaseUser:D1fficultP%40ssw0rd@mongodb0.example.com:27017,mongodb1.example.com:27017,mongodb2.example.com:27017/?authSource=admin&replicaSet=myRepl
MongoDB 安装
我已经在 Ubuntu 上安装好了MongoDB,并启动了该服务。
具体安装过程见我在 CSDN 上的文档。
* 编译 MongoDB-c-Driver
MongoDB-c-Driver 是 MongoDB 官网提供的 C 接口。
目前本地Windows上已拉下来了 1.27.0 版本的MongoDB-c-Driver、已安装了CMake,接下来使用CMake构建该项目。
生成及编译(官网)
配置 MongoDB 的 cmake 命令配置项目:3
1
cmake -S E:\CODE\Mongo_Related\mongo-c-driver\mongo-c-driver-1.29.0 -B E:\CODE\Mongo_Related\mongo-c-driver\mongo-c-driver-1.29.0\build_win32 -A Win32 -D ENABLE_EXTRA_ALIGNMENT=OFF -D ENABLE_AUTOMATIC_INIT_AND_CLEANUP=OFF -D CMAKE_BUILD_TYPE=RelWithDebInfo -D BUILD_VERSION=1.29.0 -D ENABLE_MONGOC=ON
BUILD_VERSION设置将包含在构建结果中的版本号。 它应设置为与获取源中下载的源驱动程序版本相同的值。
ENABLE_EXTRA_ALIGNMENT和ENABLE_AUTOMATIC_INIT_AND_CLEANUP是mongo-c-driver的一部分,对应于仅出于 ABI 兼容性目的而默认启用的已弃用功能。 强烈建议尽可能禁用这些功能。
ENABLE_MONGOC=OFF参数表示已禁用构建libmongoc。 我们将在下一节中构建它。
CMAKE_BUILD_TYPE设置告知 CMake 将生成哪种代码变体。对于RelWithDebInfo,将生成优化的二进制文件,但仍包含调试信息。 CMAKE_BUILD_TYPE 对多配置生成器(即 Visual Studio)没有影响,后者在构建/安装时依赖--config选项。
如果满足所有依赖项,则上述命令应成功执行并以以下内容结束:
– Configuring done (35.2s) – Generating done (2.3s) – Build files have been written to: E:/CODE/ShareCode/MongoDB/mongo-c-driver/build_
成功配置项目后,可以使用 CMake 执行构建:
1
cmake --build E:\CODE\Mongo_Related\mongo-c-driver\mongo-c-driver-1.29.0\build_win32 --config RelWithDebInfo --parallel
上面的命令大概会执行三五分钟。
继续使用下面的命令,将mongo-c-driver构建结果安装到--prefix后面的目录中:
1
cmake --install E:\CODE\Mongo_Related\mongo-c-driver\mongo-c-driver-1.29.0\build_win32 --prefix E:\CODE\Mongo_Related\mongo-c-driver\mongo-c-driver-1.29.0\install_win32 --config RelWithDebInfo
--config选项仅用于多配置生成器(即 Visual Studio),否则将被忽略。 为--config指定的值必须与为--config和cmake --build指定的值相同。
这个命令执行的很快,完成后即可在上面的文件夹中就可以看到生成的头文件和库文件:
mt 配置的编译
前提:这一步建立在已经通过 CMake 生成了 VS 项目的基础上。
目标:生成可供 mt 的 C++ 项目使用的 mongodbc 静态库。
步骤:
-
在 VS2022 中打开
mongo-c-driver.sln解决方案; -
修改项目
mongoc_static的配置为 mt;配置路径:【属性页】-【配置属性】-【C/C++】-【代码生成】-【运行库】-【多线程(/MT)】
-
修改
mongoc_static的依赖项目为 mt。经查看,mongoc_static的依赖项目有4个:bson_static、utf8proc_obj、ZERO_CHECK、zlib_obj。(若落下这一步,后面编译出来的 mongoc-static.lib 也不能给 mt 项目使用) -
在项目上右键生成,等待生成完毕,即可在生成路径中找到 mongoc-static.lib 和 bson-static.lib。
文件打包
从上面提到的路径中拷贝出所需文件,攒成下面的文件结构,就可以给 mongocxx 使用了:
1
2
3
4
5
6
7
C:\mongo-c-driver-1.29.0
├── include
│ ├── bson-1.0
│ └── mongoc-1.0
└── lib
├── bson-1.0.lib
└── mongoc-1.0.lib
* 编译 mongocxx
2025年4月15日:编译 mongocxx 应以 CSDN 上的文档为主,这里的文档有些落后。
简介
mongocxx 是基于 libmongoc 的 MongoDB 的 C++ 驱动程序的彻底重写 。它需要 C++11 编译器。众所周知,它构建在适用于86 8664Linux、macOS、Windows 和 FreeBSD 的 x 和 x - 架构上。
mongocxx 驱动程序库包含一个匹配的 bson 包 bsoncxx,它实现了 BSON 规范 。即使根本不使用 MongoDB,该库也可以独立用于对象序列化和反序列化。
根据 mongocxx 的官方文件,为连接 MongoDB 7.x 的数据库,需要安装 mongocxx 3.8+ 的版本。4
截止至 2024年8月20日,mongocxx 的最新稳定版本为 mongocxx 3.10.1 ,使用的c-driver版本为1.25.0。
截止至2025年4月11日,mongocxx 的最新稳定版本为 r4.0.0 ,使用的c-driver版本为1.29.0。
构建项目
以下是配置驱动程序的步骤:5
先打开一个cmd窗口。
下载指定版本的 mongocxx:
curl -OL https://github.com/mongodb/mongo-cxx-driver/releases/download/r4.0.0/mongo-cxx-driver-r4.0.0.tar.gz
解压:
tar -xzf mongo-cxx-driver-r4.0.0.tar.gz
将路径切换至 build:
cd mongo-cxx-driver-r4.0.0/build
手动备份一下 build 文件夹及其下的所有文件。若后面出问题的话直接复原 build 文件夹就行。
配置 C++ 驱动程序:(相关路径按需修改,下面配置是 win32、包含static项目的)
1
"C:\Program Files\CMake\bin\cmake.exe" -G "Visual Studio 15 2017" -A win32 -DCMAKE_CXX_STANDARD=17 -DCMAKE_INSTALL_PREFIX="C:\mongo-cxx-driver" -S "C:\Users\hansb\mongo-cxx-driver-r4.0.0" -B "C:\Users\hansb\mongo-cxx-driver-r4.0.0\build-32-static" -DBUILD_SHARED_LIBS=OFF
说明:
-DBUILD_SHARED_LIBS=OFF:指定编译静态库6- 若配置 mongocxx 过程中出错,需要将 build 整个文件夹删掉复原,然后再次尝试。
- 关于 boost:官方文件中说明 boost 在生成、编译过程中是可选的,因此本文在生成 mongocxx 的时候没有使用 boost。
将上述命令复制到 cmd 以后,需要等待一段时间
上述步骤全部成功的话,即可在项目上面的路径中看到 .sln 文件。
切换本地mongoc
上述命令会自动从 github 下载 mongo-c-dirver,但有时会提示连接 github 失败,这时就需要手动注入本地 C 驱动源码:
1
2
3
4
# 生成新配置(关键参数已标粗)
cmake -G "Visual Studio 15 2017" -A Win32 -DCMAKE_CXX_STANDARD=17 -DCMAKE_INSTALL_PREFIX="C:\mongo-cxx-driver" -DCMAKE_PREFIX_PATH="C:\mongo-c-driver" ^
-DBUILD_SHARED_LIBS=OFF -DBSON_LIBRARY="C:\mongo-c-driver\lib\Release\bson-static.lib" -DMONGOC_LIBRARY="C:\mongo-c-driver\lib\Release\mongoc-static.lib" -DMONGOC_INCLUDE_DIR="C:\mongo-c-driver\include" -DBSON_INCLUDE_DIR="C:\mongo-c-driver\include" -DBSONCXX_POLY_USE_BOOST=1 -DMONGOC_SOURCE_DIR="C:\mongo-c-driver-1.29.0" -DBSON_SOURCE_DIR="C:\mongo-c-driver-1.29.0" -DENABLE_AUTOMATIC_INIT_AND_CLEANUP=OFF -DBSONCXX_SYSTEM_LIB=ON -DMONGOCXX_SYSTEM_LIB=ON ^
-DCMAKE_DISABLE_FIND_PACKAGE_Git=TRUE -DCMAKE_MSVC_RUNTIME_LIBRARY="MultiThreaded" -S "C:\Users\hansb\mongo-cxx-driver-r4.0.0" -B "C:\Users\hansb\mongo-cxx-driver-r4.0.0\build-32-static"
2025年4月15日:上述命令尝试以后还是不行。放弃了。
编译mt静态库
上面已经通过 CMake 生成了 mongcxx 的解决方案,找到该 .sln 文件,用 VS2017 打开。
找到项目 mongocxx_static,查看该项目的依赖项,并查看各依赖项目的依赖项,有的依赖项重复,现将所有涉及到的项目整理如下:
- bson_static
- bsoncxx_static
- generate_libbsoncxx_static-pc(这不是个代码项目,不用改)
- generate_libmongocxx_static-pc(这不是个代码项目,不用改)
- mongoc_static
- utf8proc_obj
- zlib_obj
- mongocxx_static(这个项目的【目标文件名】记得也改个名字)
为了生成 mt 的 mongocxx.lib,需要将上面涉及到的所有项目修改为 mt 配置。
然后回到 cmd 的命令行,同样在 /build 路径,输入以下命令编译项目:
cmake --build . --config Release
(也可以直接在 VS2017 里编译出来目标静态库,但是下一步 install 可能会有问题)
打包使用文件
同样在 /build 路径,输入以下命令安装项目:
cmake --build . --target install --config Release
然后就能在 C:\mongo-cxx-driver 中看到会使用到的头文件(include文件夹)和静态库(lib文件夹)。
但是自动生成的目录有些乱,需要整理一下文件夹划分和文件名,方便后期使用。
各存储结构的合适数据量
1. 一个 Document 的字段数量限制
MongoDB 中单个文档的大小限制为 16 MB。这意味着所有字段(field-value对)的总大小不能超过这个限制。字段数量没有固定限制,但实际数量受总大小的约束。
2. 一个 Collection 中的 Document 数量
一个 MongoDB collection 中的 document 数量没有具体的限制。理论上,它可以存储数十亿的文档。然而,考虑到性能和管理的便利性,通常建议每个 collection 的 document 数量保持在数百万到数千万之间。对于更大的数据集,可能需要考虑分片(Sharding)以提高可扩展性和性能。
3. 一个 Database 中的 Collection 数量
MongoDB 中一个数据库的 collection 数量也没有硬性限制。理论上,你可以在一个数据库中创建数千个 collection。但实际上,建议根据应用的需求和数据模型来设计。如果有合理的数据分组,可以在几十到几百个 collection 之间保持管理的便利性。
4. 一个实例上的 Database 数量
一个 MongoDB 实例可以支持多个数据库,数量上没有严格限制。通常来说,一个实例上可以运行成百上千个数据库,但建议根据实际使用场景和资源配置(如内存、CPU等)来决定。过多的数据库可能会导致管理上的复杂性和性能问题。
ChatGPT的建议
- 性能:根据查询和更新的实际情况来设计数据模型,避免过于复杂的 schema。
- 管理:保持合理的 collection 和 database 数量,便于监控和管理。
- 分片:对于大规模数据集,考虑使用分片以提高性能和可扩展性。
在设计时,应该结合实际的业务需求、数据量和查询模式来作出合理的选择。
MongoDB 代替 Redis 方案
Marker 中的 redis 存储结构
- key:
前缀 + pid + 后缀,例如:"P" << pid << "E1240_" - field:
mpid + 后缀,例如:mpid << "_rank",mpid << "_cnt"
Marker 中的 MongoDB 存储结构
-
database(数据库):只建一个。
-
collection(集合):以 pid 范围分 collection。每三千万(或其它范围)个用户用一个 collection。例如 pid 介于 [1100000000, 1130000000) 之间的所有相关数据放在一个 collection 里。
-
document(文档):每个用户记录一个 document,索引
_id为 pid,每个比赛记录对应一个 field-value,field为mpid,value为一个map记录比赛信息。结构示例如下:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
{ "503906": { "awtid": 0, "cnt": 1, "ft": 1706756794, "lt": 1706756794, "mt": 1706756794, "rank": 3, "total": 24 }, "503977": { "awtid": 8132, "cnt": 232, "ft": 1724850719, "lt": 1724850719, "mt": 1724850719, "rank": 77, "total": 898 }, "_id": 1000008808 }
-
数据量分析:
-
database:所有的数据都在一个database上。
-
collection:每个collection最多会存储一亿个document。
-
document:每个document中 key-value 的数量与 mpid 的种类个数相同,经与白伟沟通,可能会有上千个比赛,也就是每个document中最多可能会有上千个 key-value。一个 key-value 的示例如下:
1 2 3 4 5 6 7 8 9
"503977": { "awtid": 8132, "cnt": 232, "ft": 1724850719, "lt": 1724850719, "mt": 1724850719, "rank": 77, "total": 898 }
-
NOS 中的 MongoDB 存储结构(初步设想)
- collection(集合):以 pid 范围分 collection。每1亿(或者再精确范围)个用户,用一个 collection,例如 pid 介于 [1100000000, 1200000000) 之间的所有相关数据放在一个 collection 里。
- document(文档):每个用户记录一个 document,索引
_id为 pid,每个积分对应一个 field-value。
MongoDB 在 TK 服务中的使用
前提要求
- TK 服务已升级为 VS2017(升级方法见文件《20240820 升级TK服务vs配置.md》)。
- Sharecode 分支切换到【UpToVS2017】,以提供 mongocxx 等第三方库。
修改配置
-
【项目属性】-【VC++目录】-【包含目录】新增 1 项:
1 2
$(TKGIT)\sharecode\ShareCode\mongo-cxx\include; $(TKGIT)\sharecode\ShareCode\MongoConnMngr;
-
【项目属性】-【VC++目录】-【库目录】新增 1 项:
1
$(TKGIT)\sharecode\ShareCode\mongo-cxx\lib;
-
【项目属性】-【链接器】-【输入】-【附加依赖项】新增 1 项:
1
mongocxx-static-rts-win32-v141-mt.lib; -
[占位符]
CMongoConnMngr
在 CMongoConnMngr 中,单例对象管理一个连接池(存储在 std::vector 中),并且这个连接池会在高并发环境中被多个线程访问和修改。为了确保线程安全,我们需要仔细考虑以下几个方面:
- 连接池的获取:多个线程可能同时请求从连接池中获取一个连接。
- 连接池的更新:单例对象会定期检查并更新连接池的内容,这可能涉及到新增、删除或修改连接。
线程安全的关键点
- 互斥锁保护共享数据:需要使用互斥锁(
std::mutex)来保护对std::vector的访问和修改。 - 条件变量:如果有线程在等待连接池中的连接变得可用,可以使用条件变量来通知这些线程。
- 单例的线程安全初始化:确保单例对象的初始化是线程安全的。
示例代码
下面是一个示例代码,展示如何实现线程安全的单例连接池管理:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
#include <iostream>
#include <vector>
#include <mutex>
#include <thread>
#include <condition_variable>
#include <memory>
#include <chrono>
// 假设 Connection 是一个类,表示连接
class Connection {
public:
bool isValid() const { return true; } // 简单示例,实际检测逻辑可复杂
// 其他连接相关的操作
};
// 单例类
class ConnectionPool {
public:
static ConnectionPool& getInstance() {
static ConnectionPool instance;
return instance;
}
// 禁用拷贝和赋值操作
ConnectionPool(const ConnectionPool&) = delete;
ConnectionPool& operator=(const ConnectionPool&) = delete;
std::shared_ptr<Connection> getConnection() {
std::unique_lock<std::mutex> lock(m_mutex);
if (m_connections.empty()) {
m_cond.wait(lock, [this] { return !m_connections.empty(); });
}
auto conn = m_connections.back();
m_connections.pop_back();
return conn;
}
void releaseConnection(std::shared_ptr<Connection> conn) {
std::lock_guard<std::mutex> lock(m_mutex);
m_connections.push_back(conn);
m_cond.notify_one();
}
void checkAndUpdateConnections() {
std::lock_guard<std::mutex> lock(m_mutex);
// 简单示例:每分钟检查并更新连接池
for (auto& conn : m_connections) {
if (!conn->isValid()) {
conn = std::make_shared<Connection>(); // 更新连接
}
}
// 如需新增连接或删除失效连接可在此执行
}
private:
ConnectionPool() {
// 初始化连接池
for (int i = 0; i < 10; ++i) {
m_connections.push_back(std::make_shared<Connection>());
}
// 启动定时检查线程
m_checkThread = std::thread(&ConnectionPool::checkConnectionsPeriodically, this);
}
~ConnectionPool() {
m_stopCheck = true;
if (m_checkThread.joinable()) {
m_checkThread.join();
}
}
void checkConnectionsPeriodically() {
while (!m_stopCheck) {
std::this_thread::sleep_for(std::chrono::minutes(1));
checkAndUpdateConnections();
}
}
std::vector<std::shared_ptr<Connection>> m_connections;
std::mutex m_mutex;
std::condition_variable m_cond;
std::thread m_checkThread;
bool m_stopCheck = false;
};
// 示例使用代码
void worker() {
auto& pool = ConnectionPool::getInstance();
auto conn = pool.getConnection();
// 使用连接进行通讯
pool.releaseConnection(conn);
}
int main() {
std::thread t1(worker);
std::thread t2(worker);
t1.join();
t2.join();
return 0;
}
代码解释
- 单例模式:
- 通过
getInstance方法获取单例对象,确保在多线程环境中只有一个实例。
- 通过
- 互斥锁和条件变量:
std::mutex用于保护对连接池的访问。std::condition_variable用于在连接池为空时阻塞请求线程,并在有连接可用时通知等待的线程。
- 连接的获取和释放:
getConnection方法获取一个连接。如果连接池为空,线程将被阻塞,直到有连接可用。releaseConnection方法将连接归还到连接池,并通知一个等待的线程。
- 连接池的定期检查和更新:
checkAndUpdateConnections方法检查连接池中的连接是否有效,并在需要时更新。- 一个独立的线程
m_checkThread每分钟调用一次checkAndUpdateConnections方法。
- 线程安全的单例初始化:
- 使用 C++11 的
static关键字确保单例实例的线程安全初始化。
- 使用 C++11 的
需要注意的点
- 异常处理:
- 在实际代码中,需要考虑异常处理,确保在任何异常情况下都能正确释放锁。
- 性能优化:
- 在高并发环境中,频繁的锁操作可能会带来性能瓶颈。可以考虑使用读写锁(
std::shared_mutex)或其他并发数据结构来优化性能。
- 在高并发环境中,频繁的锁操作可能会带来性能瓶颈。可以考虑使用读写锁(
- 连接的有效性:
- 连接的有效性检查和更新逻辑根据实际需求来实现,示例代码中只是一个简单的示意。
- 优雅的停止检查线程:
- 在单例销毁时,确保检查线程能够优雅地停止。
通过上述设计和实现,可以确保在高并发环境中对连接池的安全访问和更新。
mongoClusterDefine
MaxPoolSize; // mongocxx::pool 创建的最大客户端数量(在池中和签出)。 默认值为100 。 一旦达到该阈值,mongocxx::pool::acquire 就会阻塞,直到另一个线程将客户端返回到池中。
MinPoolSize; // mongocxx::pool 空闲时的大小。 一旦创建了这么多的客户端,池中的客户端就不会少于这么多。 如果创建了超过 minPoolSize 的其他客户端,则它们在返回到池中时将被销毁。 默认值为 " 0 ",即禁用此功能。 禁用后,客户端永远不会被销毁。
参考 712839101112131445615
-
ChatGPT ↩︎