积分下线流程
[TOC]
2024 积分下线流程
1. Hive上的数据聚合
1)工作流介绍
-
【小海豚10.11.199.44】-【行为数据组-sql】-【积分下线_2024】
这个工作流是用来测试脚本和代码的,后面用来跑指定某天的CMA数据。
-
【小海豚10.11.199.44】-【行为数据组-sql】-【PyHiveTidyUpEidHistory】
这个工作流是为了调用 SQL 脚本
EVT_SQL_2024/sql_evt_hdfs2hive_history.sql。在工作流中,获取当前和180天前的日期,传入 SQL 脚本中,以供使用。
2)Hive上的数据聚合
这一步是通过小海豚调用 SQL 脚本EVT_SQL_2024/sql_evt_hdfs2hive_history.sql实现的。
大致思路如下:
-
读取 HDFS 上 CMA 的历史数据(datalake_platform.cma_hudi 表),筛选出与 EVT 相关的所有数据,插入到
cma. base_evt表中,仅保留三个字段,字段与字段含义如下:- oper_ts(时间戳)
- oper_type(CMA监控项)
- eid(在该时间点,该监控项出现的次数)
-
经上一步筛选出的数据,经检查发现 cma.base_evt 表中存在 oper_ts(时间戳)与 oper_type(CMA监控项)相同的重复项,分析是不同实例的上报结果。将数据进一步整理:按照 oper_ts 与 oper_type 进行分组,相同项的 eid 求和后保留,数据整理后插入到
cma.base_evt_ts中,该表中的字段含义与cma. base_evt中字段含义相同。 -
对上表中的数据再次聚合。
对于每种 oper_type(CMA监控项)进行整合,oper_ts(时间戳)保留最大,eid 取和。将上述整理好的数据插入到 cma.ads_evt_ops_status 表中。
cma. ads_evt_ops_status表中字段与字段含义如下:- oper_ts(统计周期内,该CMA监控项最后出现的时间)
- oper_type(CMA监控项)
- eid(统计周期内,该监控项出现的次数)
3)HDFS 中涉及到的表的体量
上述思路中提到的三张 Hive 表,数据体量如下:
| 表名 | 数据量(条) |
|---|---|
| datalake_platform.cma_hudi | 39490929153 |
| cma.base_evt | 145138106089 |
| cma.ads_evt_ops_status | 20179 |
用于统计上述信息的 HiveSQL 语句如下:
1
2
3
SELECT COUNT(*) AS total_count FROM datalake_platform.cma_hudi WHERE pt_dt BETWEEN '2024-01-29' AND '2024-07-30';
SELECT COUNT(*) AS total_count FROM cma.base_evt;
SELECT COUNT(*) AS total_count FROM cma.ads_evt_ops_status;
4)Impala 介绍
Impala 会先把数据加载到内存中,相对 hive 直接在硬盘上处理数据会快非常多,Impala 初始化数据:
1
2
TRUNCATE TABLE cma.ads_evt_ops_status;
TRUNCATE TABLE cma.base_evt;
也可以先这样清理一下缓存:
2. Hive 到 MySQL
HDFS 的 cma.ads_evt_ops_status 在 每天 15:00 被同步到外网的 MySQL 的 rsp_datagovern.ads_evt_ops_status_ago表中。
执行语句如下:(来自陆贺)
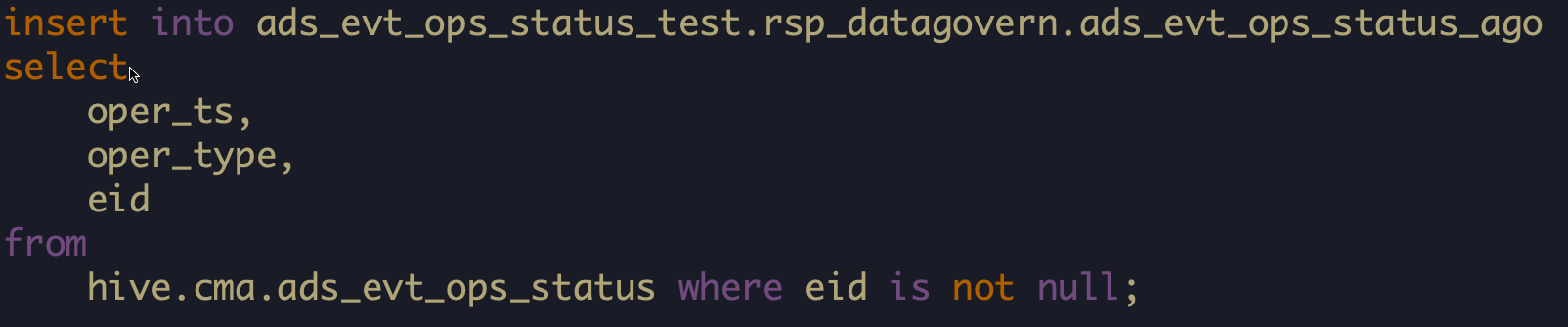
需要注意的是,上述内容是追加插入的。也就是说,如果 HDFS 中表 cma.ads_evt_ops_status 的数据不清空,每天 15:00 都会被追加同步到 MySQL 中。需要注意及时清空 HDFS 中的数据!
清理语句:
1
2
TRUNCATE TABLE cma.ads_evt_ops_status;
TRUNCATE TABLE cma.base_evt;
3. MySQL 上的数据整理
1)基本信息
-
这一步是通过
PyTidyUpEid4Downline.py脚本来进行数据批处理的 -
内网就在本地跑就行;外网的得在小海豚上跑,小海豚路径为:
10.30.130.17 - TK服务 - PyTidyUpEid4Downline
-
本地和小海豚上跑的时候,目标表不同,但根本的数据源都是 HDFS 的 ads_evt_ops_status 表。
-
因为内外网上 CVS 积分的信息是不同的,所以脚本在内外网 CVS 数据库上统计出来的下线积分情况会略有不同,原则上,应该以外网数据为准,实际上,内网统计出来的数据要稍微多一些。
2)内外网的不同
- 数据源:
- 内网:本地 MySQL 的 cma.ads_evt_ops_status_ago 表。(将 HDFS 上 cma.ads_evt_ops_status 表的数据导出为 csv,然后再将 csv 插入到本地 MySQL 表)
- 外网:外网机上 MySQL 的 rsp_datagovern.ads_evt_ops_status_ago 表
3)python 脚本的思路
- 读取数据源 MySQL 表 ads_evt_ops_status_ago,数据整理为一个字典,键值为积分 id,右值为以下形式:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
{ 'que': { 'count': 0, # 总查询次数 'last_time': None, # 最近一次单独查询的时间 'last_time_by_tag': None # 最近一次通过积分域查询的时间 }, 'upd': { 'count': 0, # 总修改次数 'last_time': None, # 最近一次单独修改的时间 'last_time_by_tag': None # 最近一次通过积分域修改的时间 }, 'last_modify_time': None, 'people': None, 'lv1': None, 'lv2': None, 'description': None, 'table': None, 'modeltype': None, 'cluster': None, 'demand': None }
-
遍历所有 MySQL 表
define_nosdata_*中的所有积分,选择所有status > 0的积分,将遍历到的所有积分信息补充到上一步生成的字典中;记录所有异常(只读不写、只写不读、不读不写)的积分。 -
输出所有的异常积分信息到命令行、本地日志、邮件给自己。若是本地内网的话,还会写为一个 Excel。
- 需要特殊说明一下:若是小海豚+外网,可以从日志里拷贝输出的异常积分信息,直接粘贴到 Excel 中,即可生成表格。
4. Excel 中对异常积分进行筛选
- 到这一步已经得到了统计周期内的所有异常积分:只读不写、只写不读、不读不写三种情况。
- 找芒哥根据业务和 last_modify_time 大致确定一下可以下线的积分。
- 找积分的业务方确定一下可以下线的积分。
5. 下线积分 (-80)
1)基本信息
-
这一步是通过
PyExcelEid2Downline.py脚本来进行数据批处理的。 -
内网就在本地跑就行;外网的得在小海豚上跑,小海豚路径为:
10.30.130.17 - TK服务 - PyExcelEid2Downline
-
因为内外网上 CVS 积分的信息是不同的,所以脚本在内外网 CVS 数据库上下线积分情况会略有不同。
-
内外网的目标表是不同的,所以必须内网跑一遍,外网也得跑一遍。必须按照先内网再外网的顺序来跑,因为外网信息需要依赖内网跑完以后的结果(具体操作见下面)
2)获取下线积分的存储结构
- 脚本试跑:内外网执行脚本前,都先将脚本中的
B_DEBUG参数设为True,试跑一遍,得到下线积分列表DOWNLINE_EIDS。 - 获取所有下线积分的存储结构:将上面得到的
DOWNLINE_EIDS拷贝到脚本PyGetQUERYSTRUCT_EVT.py中作为源数据,执行该脚本,获取所有积分的存储结构,为后期清理积分做准备。 - 注意事项:必须要在下线积分(将积分 status 置为 -80)之前获取积分的存储结构,否则在积分下线后,积分失效,就无法获取存储结构了。
3)python 脚本的思路
- 读取需要下线的积分信息。这一步内外网的数据源是不同的:
- 内网:从脚本同路径下的
"确认下线积分.xlsx"文件中,读取已经标记好的可以下线的积分信息; - 外网:将脚本在内网中下一步的输出结果拷贝到本脚本的
DOWNLINE_EIDS中,执行时直接从该对象取值。
- 内网:从脚本同路径下的
- 输出所有即将下线的积分信息。将信息输出到命令行、日志。(外网会依赖这一步的输出结果)
- 备份数据库。将可能会修改到的所有 MySQL 表进行备份。这一步内外网的方法是不同的:
- 内网:将
define_nosdata_*和define_nostag_*表备份到本地 localhost 数据库中; - 外网:通过堡垒机手动将上述几个数据导出为 csv 进行备份。
- 内网:将
- 下线积分。需要注意的是,UPDATE 表的时候,不要修改 last_modify_time 的值,且需要将同 id 下所有 status>0 的项置为 -80。
- 输出实际下线的积分信息。将信息输出到命令行、日志、发邮件给自己。这一步是为了统计信息和自己校核。
- 观察 CMA 中有没有异常报错。
4)实操
2024年8月2号,下线(置为-80)了一批积分,下线统计信息如下:
- 下线积分所在集群的统计信息:
| 集群 | Excel中筛选出的个数 | 内网实际下线个数 | 外网实际下线个数 |
|---|---|---|---|
| redis_evt_A | 187 | 187 | 111 |
| redis_evt_AA | 58 | 58 | 58 |
| redis_evt_old | 85 | 85 | 85 |
| redis_mq | 934 | 934 | 893 |
| redis_flag | 13 | 13 | 13 |
| 总 | 1277 | 1277 | 1160 |
- 下线积分涉及到的 MySQL 表信息:
| MySQL表 | 内网个数 | 外网个数 |
|---|---|---|
| define_nosdata_general | 330 | 254 |
| define_nosdata_mqzdr | 934 | 893 |
| define_nosdata_flag | 13 | 13 |
| 积分总个数 | 1277 | 1160 |
| define_nostag_general | 12 | 15 |
| define_nostag_mqzdr | 37 | 36 |
| define_nostag_flag | 2 | 2 |
| 积分域总个数 | 51 | 53 |
6. 清理积分数据
1)基本信息
- 将积分下线后(置为-80),观察 1 个月是否有用户反馈,若没有反馈,就开始清理 Redis 的积分数据。
- 清理积分数据前必须知道该积分的存储结构。(下线积分前整理出所有积分的存储结构)
2)预备工作:获取积分的存储结构
- 注意事项:这一步必须在积分实际下线前(将积分的 status 置为 -80)执行。
- 获取方法:这一步是通过在本地执行
PyGetQUERYSTRUCT_EVT.py来实现的。 - python 脚本思路:
- 准备原始数据:此脚本需要首先给出需要查询存储结构的所有积分。在本文中,此脚本的数据来自于
B_DEBUG = True时执行脚本PyTidyUpEid4Downline.py得到的积分统计信息。 - 查询存储结构:建立内网的 socket 连接,循环所有待查询的积分,调用 NOS 提供的积分查询的接口,查询所有积分的存储结构。
- 结果整理:将上述查询到的结果整理为
下线积分存储结构信息.xlsx,以供后面使用。
- 准备原始数据:此脚本需要首先给出需要查询存储结构的所有积分。在本文中,此脚本的数据来自于
3)积分清理
-
前置工作:得到所有积分的存储结构后,就可以联系 DBA(吕开心)进行积分数据清理。
-
清理方法:经与吕开心沟通,清理方法如下:
-
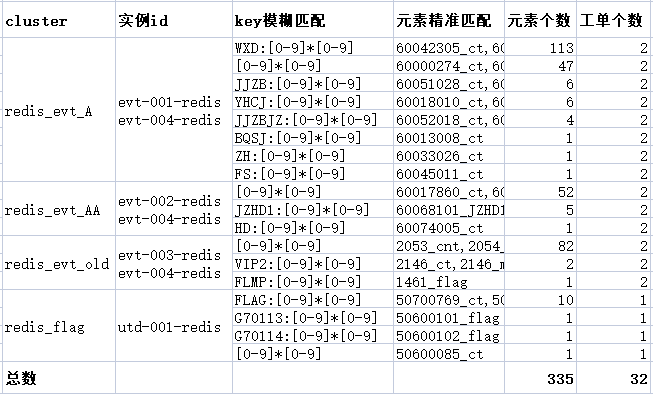
redis_mq 集群:因为集群中的 key 数量多、种类杂,全都交给吕开心处理。
- 其它 4 个集群:
- key 和 field 都需要模糊匹配的,我把这些积分的存储结构整理出来,交由吕开心处理。
- 只 key 需要模糊匹配,我自己提工单即可。
-
详细分表如下:(红框的3个表交由吕开心,剩下的4个表我提工单)

-
4)实操
20240902 联系吕开心开始处理。
提工单详情见Excel表【清理积分-2024年9月2日1004.xlsx】,截图如下:
5)redis 清理结果
见文档《2024-10-30-积分清理结果.md》
旧积分下线流程
积分下线流程
1. CMA 数据落盘
Hive 中存储了来自 CMA 的落盘数据,路径如下:
地址:http://10.11.199.18:8889/hue
数据路径:/cma_bigdata/tks/NOSEVT(读权限),库名:cma(读写权限)
数据路径即为 hdfs 的路径,CMA 的数据通过流处理,每天写入对用日期的文件中,例如: /cma_bigdata/tks/NOSEVT/2022/7/29
2. 调用 sql 脚本
脚本路径:【小海豚】-【行为数据组-sql】-【积分下线】
该脚本每天上午11点执行一次,脚本内容见文件 ”积分下线.py“ ,思路大致为:通过参数攒出来一条命令执行。
该命令形如:
/usr/local/bin/h2cmd -f EVT_SQL/evt_daily_hdfs2hive.sql -hiveconf PT_YEAR=${pt_year} -hiveconf PT_MONTH=${pt_month} -hiveconf PT_DAY=${pt_day}
这条命令用于在 Hive 环境中执行一个 SQL 脚本,具体解释如下:
-
/usr/local/bin/h2cmd:这是一个可执行文件的路径,可能是一个自定义的命令行工具或脚本,用于与 Hive 进行交互。根据上下文,这个命令可能用于在 Hive 中执行 SQL 脚本。 -
-f EVT_SQL/evt_daily_hdfs2hive.sql:这个选项后面跟着一个文件路径,表示要执行的 SQL 脚本文件。在这个例子中,evt_daily_hdfs2hive.sql是一个 SQL 文件,位于EVT_SQL目录下。这个文件包含了一系列的 SQL 语句,这些语句将会被执行。 -
-hiveconf PT_YEAR=${pt_year}:这个选项用于传递 Hive 配置参数。在这个例子中,PT_YEAR被设置为${pt_year}的值。${pt_year}是一个变量,通常在执行命令时会被替换为实际的年份值(如2024)。这样,SQL 脚本中的PT_YEAR可以动态获取这个值。 -
-hiveconf PT_MONTH=${pt_month}:这个选项类似于上面的选项,用于传递月份的值。PT_MONTH被设置为${pt_month}的值,${pt_month}是一个变量,会在执行命令时替换为实际的月份值(如01或07)。 -
-hiveconf PT_DAY=${pt_day}:同样,这个选项是用来传递日期的值,PT_DAY被设置为${pt_day}的值,${pt_day}是一个变量,在执行时会被替换为实际的日期值(如01或21)。
整体而言,这条命令的目的是使用 h2cmd 工具执行一个名为 evt_daily_hdfs2hive.sql 的 SQL 脚本,并通过 Hive 配置参数传递特定的年份、月份和日期值。
3. 在 Hive 上进行数据整理
evt_daily_hdfs2hive.sql 脚本在上一步被调用,该脚本的思路大致如下:
-
创建和配置一张外部表
cma.src_evt作为数据来源。2024.07.18:应该从 CMA 获取数据,将处理后的数据每天覆写到这张表,但不知道具体方式、时间、执行人。
2024.07.22:应该是 CMA 那边通过流处理每天自己写的这个表,实际并不是我们创建的。
-
填充数据至
cma.base_evt:(该表包含三个字段:oper_ts,oper_type,eid)-
从
cma.src_evt表中提取数据,解析 JSON 对象,提取所需字段; -
将处理的数据插入到
cma.base_evt表中。
-
-
填充数据至
cma.ads_evt_ops_status:(该表结构与cma.base_evt一致)-
从
cma.base_evt表中选择数据,按oper_type分组,计算每个操作类型的最大时间戳和事件ID的总和; - 如果事件ID的总和大于0,则将
eid设置为1,否则设置为0。 - 从
cma.base_evt表中选择数据,计算过去24小时内不同操作时间戳的数量; - 将这些数据插入到
cma.ads_evt_ops_status表中,操作类型为checkCount,事件ID为不同操作时间戳的数量。
-
-
最后,得到了两张表:
-
cma.base_evt:包含当天 CMA 在各个时间点、每个监控指标出现的数量。(推测是这些) -
cma.ads_evt_ops_status:当天,该监控指标出现的最大时间,以及是否出现。
另外,
oper_type字段中checkCount对应的内容应为当天时间戳的种类个数,理论上来说应为1440。 -
4. Hive 迁移到 MySQL 上
Hive 的 cma.ads_evt_ops_status 需要同步到 MySQL 的 rsp_datagovern.ads_evt_ops_status_ago 表中。
每天 15:00 执行如下语句:(来自陆贺)
5. 将 hive 上的数据再整理到 MySQL 上
脚本路径:【小海豚】-【TK服务】-【evt-python-guopc-EVT积分下线每日数据检测导入】
该脚本目前已下线,脚本内容见”evt-python-guopc-EVT积分下线每日数据检测导入.py“ ,思路大致如下:
-
在
ads_evt_ops_status_ago表中查询当天的数据,确认包含checkCount字段,并且eid值等于1440; -
将
ads_evt_ops_status_ago表中前一天的数据,插入到ads_evt_ops_status表中,避免重复数据。如果遇到重复键(oper_type为键),则更新相关字段。 -
删除
ads_evt_ops_status_ago表中一周以前的数据。 -
以上提到的两张表分析其功能:
-
ads_evt_ops_status_ago:来自 Hive 的数据,见上面一步。 -
ads_evt_ops_status:对所有历史数据的整合,每个oper_type对应的oper_ts表示该字段最后一次更新的时间,eid代表历史以来一共更新了多少次。
-
6. 分析 MySQL 中需要下线积分的数据
脚本路径:【小海豚】-【TK服务】-【evt-python-guopc-EVT积分下线】
该脚本目前已下线,脚本内容见”evt-python-guopc-EVT积分下线.py“ ,思路大致如下:
- 获取半年内的有过查询/写入的积分数据,并将其分类到
que_eids,que_tags,upd_eids,upd_tags集合中。 - 获取域积分关联的积分 ID,并将其添加到相应的集合中。
- 获取正在生效的所有积分,并筛选出半年内不查不改的数据。
- 发送邮件通知业务方和团队某些积分将在一个月后下线。
两个脚本
积分下线涉及到两个 SQL 脚本,一个用于每天整理来自 CMA 的数据(evt_daily_hdfs2hive.sql),一个用于整理历史 CMA 数据(evt_history_hdfs2hive.sql)。
问题
与赵拓讨论能否恢复从 CMA 落盘数据到cma.src_evt的链路,赵拓:
- 数据来源,是否为TKSDK上报的指标?
- 是否需要历史数据,历史数据 CMA 只有三个月的,而且都是原始数据,若我们直接拿原始数据来处理,会戳现在 CMA 那边的监控指标造成很大的压力,必报警。
- 以后怎么办,建议直接订阅 CMA 的 Topic,从 Flink 上自己处理,落盘数据。
异常积分分析
- 筛选目标:
- 近半年内没有读写记录的积分
cluster仅限:[‘redis_mq’, ‘redis_evt_A’, ‘redis_evt_old’, ‘redis_evt_AA’, ‘redis_flag’]modeltype仅限:normal
- 筛选结果见 Excel 表:
异常积分信息_筛选后_2024年7月31日1527.xlsx
集群与redis集群的对应关系
- redis_evt_A:evt-001-redis、evt-004-redis
- redis_evt_AA:evt-002-redis、evt-004-redis
- redis_evt_old:evt-003-redis、evt-004-redis
- ssdb_evt_manage:evtcycle-001-ssdb、evt-004-redis
- ssdb_evt_B:evtssdb-001-ssdb、evt-004-redis
- ssdb_evt_C:marker-001-ssdb
- redis_evt_SSDB:evt-003-redis
- redis_mq:mengqiu-001-redis
- redis_flag:utd-001-redis
- redis_fish:qpfish-001-redis
- redis_jjfish:jjfish-001-redis
思考
积分下线/清理工作费时费力,以后应从源头开始,严格控制所有积分的生命周期(ttl)。
费时费力主要体现在以下几点:
- 整理出异常积分后,还需要人工进行筛选,上千个积分都需要人工过一遍;
- DBA 拿到数据清理的工单后,需要进行长时间的扫描、清理工作,有些积分的匹配规则比较麻烦,只能先扫描再删除,过程麻烦且耗时。