新gss Mongodb模型性能测试
目标
新GSS的数据模型有两个:MongoArrayModel 和 MongoSingleModel,这两个数据模型的使用场景有重叠,现针对这两个模型,测试同一个业务的 “增删改查” 效率。以便后面确定具体使用哪一个数据模型。
业务介绍
1)业务配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
{
"maxLen": 100, // 数组长度(唯一索引字段下,数据保留条数)
"keyField": [ // 索引字段
"userid",
"gameid",
"mpid"
],
"valueField":[ // 数据字段
"round",
"result",
"role"
],
"expireTime": 86400 // 过期时间
}
2)ModelArray表
索引设置
| Name & Definition | Type | Size | Properties | Status | |
|---|---|---|---|---|---|
| _id_ | regular | 16.0 MB | unique | Ready | |
| updateAt_1 | regular | 12.9 MB | TTL | Ready | |
| userid_1_gameid_1_mpid_1 | regular | 34.1 MB | unique compound | Ready |
上表的 Size 是在有效数据为 5000W 条、ModelArray 表中 doc 个数为 50W 个时的数据。
Document示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
{
"_id": {
"$oid": "6790c223b6a028b5bf30364a"
},
"createAt": {
"$date": "2025-01-22T08:21:08.448Z"
},
"updateAt": {
"$date": "2025-01-22T08:21:08.448Z"
},
"gameid": 1105,
"mpid": 77080,
"userid": 10000001,
"gamedata": [
{
"round": 57,
"result": "Win",
"role": "Prince",
"_id": "6790615ca6faf6b3a1a8f40a",
"_ts": {
"$date": "2025-01-22T03:09:16.490Z"
}
},
{
"round": 57,
"result": "Win",
"role": "Prince",
"_id": "6790615ca6faf6b3a1a8f579",
"_ts": {
"$date": "2025-01-22T03:09:16.687Z"
}
}, ...
]
}
3)ModelSingle表
索引设置
| Name & Definition | Type | Size | Properties | Status | |
|---|---|---|---|---|---|
| _id_ | regular | 1.6 GB | unique | Ready | |
| updateAt_-1 | regular | 941.0 MB | TTL | Ready | |
| userid_1gameid_1_mpid_1_updateAt-1 | regular | 3.1 GB | unique compound | Ready |
上表的 Size 是在有效数据为 5000W 条、ModelSingle 表中 doc 个数为 5000W 个时的数据。
Document示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
{
"_id": {
"$oid": "6790aa74acfaace9b517ab59"
},
"userid": 10000006,
"gameid": 1105,
"mpid": 77019,
"round": "66",
"result": "Draw",
"role": "Emperor",
"createAt": {
"$date": "2025-01-22T08:21:08.448Z"
},
"updateAt": {
"$date": "2025-01-22T08:21:08.448Z"
}
}
测试环境
1)数据库
MongoDB:使用 DBA 提供的测试环境 MongoDB,连接信息如下:
1
mongodb+srv://dev_xwsjz_rwh:dev_xwsjz_rwh_JJMatch@service.jjdev.local/admin?tls=false&srvServiceName=devxwsjz-001-mongodb
Database:新建一个专门用于本次测试的数据库 GSS_test
Collection:
- myTest:测试不同的文档结构
- testArray:测试模型 ModelArray,目前包括 5W 条数据。
- testSingle:测试模型 ModelSingle,并且将
updateAt字段设置为了 TTL。 - testModelArray:测试模型 ModelArray,目前包括 50W 条数据。
- testModelSingle:测试模型 ModelSingle,目前包含 5000W 条数据。
2)测试服务
GSS:简单实现功能的 Mongo 模型。Git 分支:feature/20250113UseMongoModel。
Store:增加了向 GSS 发送测试消息的代码。Git 分支:feature/20250120TestNewGSS。不同的测试内容通过硬编码实现,编译出不同的 exe 实现对应的测试功能,例如 TKHisStoreService_test_1_*.exe 就是测试 case 1 时的功能。不同的 case 对应不同的测试函数和内容。
3)测试机器
新GSS:部署在 192.168.7.137 上。
测试Store:本地、192.168.7.137、192.168.7.44、192.168.7.101 四台机器按需部署
4)MongoDB
使用 DBA 提供的内网 MongoDB 环境,该环境为副本集架构、单机多实例模式。
内网与外网的配置是不一样的:外网 his-mongo 是分片集群架构、每个虚机都是单实例部署。
使用内网环境测试可以测试出在MongoDB最小配置下的性能表现情况,更易压测到性能瓶颈。
测试流程
2025年1月22日:
- 12:00 ~ 15:40 Mongo总数据量:10W,ArrayModel 单次25个查询测试
- 13:58 ~ 14:20 Mongo总数据量:10W,SingleModel 单次25个查询测试
- 15:10 ~ 15:38 Mongo总数据量:50W,ArrayModel 单次25个查询测试
- 15:44 ~ 16:05 Mongo总数据量:50W,SingleModel 单次25个查询测试
- 16:05 ~ 16:14 ArrayModel 插入数据到100W
- 16:15 ~ 16:28 SingleModel 插入数据到100W
- 16:36 ~ 16:56 Mongo总数据量:100W,ArrayModel 单次25个查询测试
- 17:15 ~ 17:40 Mongo总数据量:100W,SingleModel 单次25个查询测试
- 17:47 ~ 18:36 SingleModel 插入数据到 500W
- 17:50 ~ 17:51 ArrayModel 通过手动插入CSV文件,数据扩充到 500W
- 18:44 ~ 19:05 Mongo总数据量:500W,SingleModel 单次25个查询测试
- 19:23 ~ 19:40 Mongo总数据量:500W,SingleModel 单次1个查询测试
- 19:43 ~ 20:00 Mongo总数据量:500W,SingleModel 单次100个查询测试
- 20:02 ~ 20:17 Mongo总数据量:500W,ArrayModel 单次1个查询测试
- 20:20 ~ 20:35 Mongo总数据量:500W,ArrayModel 单次25个查询测试
- 20:38 ~ 20:55 Mongo总数据量:500W,ArrayModel 单次100个查询测试
- 20:54 ~ 21:01 SingleModel 通过手动插入CSV文件,数据扩充到 1000W
- 21:02 ~ 21:20 Mongo总数据量:1000W,SingleModel 单次25个查询测试
- 21:17 ~ 21:20 ArrayModel 通过手动插入CSV文件,数据扩充到 1000W
- 21:31 ~ 22:00 Mongo总数据量:1000W,ArrayModel 单次25个查询测试
- 22:00 ~ 22:20 ArrayModel 通过手动插入CSV文件,数据扩充到 5000W
- 22:30 ~ 23:30 SingleModel 通过手动插入CSV文件,数据扩充到 5000W
- 23:40 ~ 24:00 Mongo总数据量:5000W,SingleModel 单次25个查询测试
- 24:03 ~ 24:28 Mongo总数据量:5000W,ArrayModel 单次25个查询测试
2025年2月10日:
- 15:15 ~15:49 本地部署并启动
TKHisStoreService_test_stress_60_2.exe,该测试程序会启动60个写入线程和2个读取线程。 - 15:50 ~ 16:06 在 192.168.7.44 上部署并启动
TKHisStoreService_test_stress_60_2.exe。 - 16:07 ~ 16:22 在 192.168.7.101 上部署并启动
TKHisStoreService_test_stress_60_2.exe。 - 16:23 ~ 在 192.168.7.90 上部署并启动
TKHisStoreService_test_stress_60_2.exe。
基本功能测试
1)写入
ArrayModel 写入测试
| 请求线程数 | maxLen | GSS写入并发量(k/min) | GSS写入时延(ms) | 备注 |
|---|---|---|---|---|
| 1 | 20 | 17.42~18.95 | 2.76~3.02 | 随机插入(带截断) |
| 2 | 20 | 32.51~32.92 | 3.08~3.20 | 随机插入(带截断) |
| 5 | 20 | 60.85~66.37 | 4.25~4.51 | 随机插入(带截断) |
| 10 | 20 | 95.41~104.1 | 5.28~5.57 | 随机插入(带截断) |
| 10 | 100 | 67.76~80.91 | 7.03~8.50 | 随机插入(带截断) |
| 10 | 100 | 96.57~102.38 | 5.45~5.62 | userid顺序插入(不触发截断) |
SingleModel 写入测试
插入新 doc,超过 maxLen 的数据不做处理:
| 请求线程数 | GSS写入并发量(k/min) | GSS写入时延(ms) | 备注 |
|---|---|---|---|
| 10 | 111.35~124.36 | 4.30~4.83 | 直接插入,无截断功能 |
插入新 doc,同时提取超过 maxLen 的 doc 的 oid,然后指定 oid 进行删除:
| 请求线程数 | GSS写入并发量(k/min) | GSS写入时延(ms) | 备注 |
|---|---|---|---|
| 10 | 73.93~77.16 | 7.48~7.79 | userid 顺序插入(没有超过maxLen的数据) |
| 10 | 57.34~58.8 | 9.84~10.14 | userid 随机插入(有超过maxLen的数据) |
2)删除
| 请求线程数 | GSS写入并发量(k/min) | GSS写入时延(ms) |
|---|---|---|
| 10 | 220.21~228.44 | 2.55~2.68 |
3)修改
| 请求线程数 | GSS查询并发量(k/min) | GSS查询时延(ms) |
|---|---|---|
| 10 |
目前还未测试。
可以参考 ArrayModel 的写入效率,因为 ArrayModel 的写入同样也是调用的
UpdateOne()函数。
4)查询
查询性能表现为:collection 中数据量越大、查询的数据量越大,查询延迟越高。
以下所有测试均为 10 个线程通过 while 循环压测至少 20 分钟的结果。
MongoDB数据量对查询效率的影响
下表为单次请求 25 个数据,在 MongoDB 中有不同数据量时,GSS 中两种 Mongo 模型的查询性能表现情况。
| Mongo有效数据 | Array并发量 (k/min) | Array延迟 (ms) | Single并发量 (k/min) | Single延迟 (ms) |
|---|---|---|---|---|
| 10W | 312~341 | 0.97~1.00 | 275~286 | 1.15~1.17 |
| 50W | 332~343 | 0.98~1.00 | 279~290 | 1.13~.1.15 |
| 100W | 337~345 | 0.97~0.99 | 282~293 | 1.11~1.13 |
| 500W | 271~331 | 1.01~1.07 | 237~276 | 1.11~1.13 |
| 1000W | 334~342 | 1.00~1.02 | 236~284 | 1.12~1.17 |
| 5000W | 322~350 | 0.998~1.09 | 277~286 | 1.12~1.14 |
请求数据量对查询效率的影响
下表为MongoDB中有500W条数据时,单次请求不同数据量时,GSS中两种Mongo模型的查询性能表现情况。
| 单次请求数量(个) | Array并发量 (k/min) | Array延迟 (ms) | Single并发量 (k/min) | Single延迟 (ms) |
|---|---|---|---|---|
| 1 | 521~578 | 0.666~0.695 | 506~588 | 0.637~0.662 |
| 25 | 271~331 | 1.01~1.07 | 237~276 | 1.11~1.13 |
| 100 | 163~178 | 1.71~1.74 | 124~129 | 2.28~2.34 |
MongoArray 测试查询 Element:
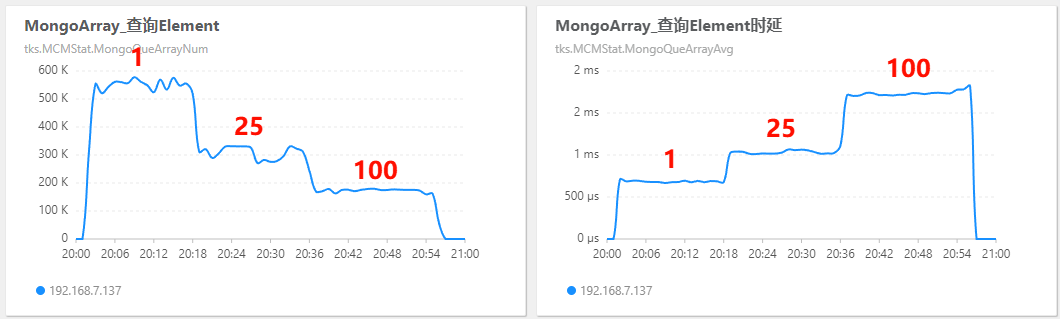
5)结论
- 上游请求越多(写入线程数多),GSS 并发量越高,写入时延越高。
- 写入速度从快到慢:
- SingleModel 不按照 maxLen 截断(4.30~4.83 ms)
- ArrayModel 按照 maxLen 截断(7.03~8.50 ms)
- SingleModel 按照 maxLen 截断(9.84~10.14 ms)
- ArrayModel 按照 maxLen 截断 + 按照TTL移除过期元素(未测试,从复杂度上推测此查询最慢)
- 查询效率:
- ArrayModel 的查询效率略高于 SingleModel:
- 查询并发量:ArrayModel 为 SingleModel 的 1.2 倍左右。
- 查询时延:SingleModel 为 ArrayModel 的 1.1 倍左右。
- 在测试范围内(0~5000W 条),MongoDB 集合中的整体数据量对查询效率基本没有影响。
- 单次请求数据量越多,查询的时延越高。
- ArrayModel 的查询效率略高于 SingleModel:
- 【占位】
压力测试
1)测试目标
-
最大吞吐量下,GSS 的 Mongo 模型的表现性能。
-
模拟在真实业务场景下(1:30 的读写比例),GSS 的 Mongo 模型表现情况。
现在真实业务情况下 GSS 的读写情况:写入:73 k/min,读取:2.4 k/min。比例为 30:1 。
2)测试流程
- 硬编码测试程序:硬编码用于测试的 Store,生成 60 个写入线程和 2 个读取线程(用于模拟实际生产中的 1:30 的读写比例),分别向 ModelArray 和 ModelSingle 模型发送请求。
- 依次部署测试程序:分别在4台机器上,每间隔 20 分钟左右,依次部署上述测试程序。
- 观察指标变化:在 CMA 面板上监控 GSS 服务的状态。
3)测试结果
测试情况:
| 部署 Store_test 数量 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| 写入总线程数(个) | 60 | 120 | 180 | 240 |
| 读取总线程数(个) | 2 | 4 | 6 | 8 |
| GSS-CPU使用率(%) | 14~18 | 20~22 | 22~26 | 24~27 |
| Mongo-CPU使用率(%) | 42~44.9 | 52.4~57.3 | 53.5~63.2 | 59.7~66.1 |
| Mongo-连接数(个) | 66~71 | 88~100 | 118~121 | 131~133 |
开始测试前,GSS 服务器的 CPU 使用率小于 1%;Mongo 服务器的 CPU 使用率小于 3%;Mongo 的连接数为54~55。
读写量统计:
| 部署 Store_test 数量 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| Array写入量(k/min) | 63.69~66.57 | 97.33~99.64 | 106.94~116.19 | 117.18~122.51 |
| Array读取量(k/min) | 2.30~3.12 | 4.10~4.66 | 7.50~12.05 | 5.92~11.22 |
| Single写入量(k/min) | 49.47~51.29 | 74.02~77.46 | 83.81~90.03 | 93.17~98.00 |
| Single读取量(k/min) | 52.03~54.05 | 77.58~81.51 | 91.90~101.63 | 97.81~108.23 |
| Single删除量(k/min) | 49.60~54.34 | 77.58~81.51 | 91.90~101.63 | 97.81~108.23 |
读写时延统计:(GSS的统计时延)
| 部署 Store_test 数量 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| Array写入时延(ms) | 7.14~7.55 | 9.44~9.71 | 11.81~12.63 | 13.57~14.60 |
| Array读取时延(ms) | 1.18~1.24 | 1.41~1.49 | 1.58~1.67 | 1.70~1.98 |
| Single写入时延(ms) | 6.85~7.11 | 9.06~9.32 | 11.41~12.27 | 13.13~14.13 |
| Single读取时延(ms) | 1.28~1.35 | 1.62~1.67 | 2.02~2.05 | 2.35~2.46 |
| Single删除时延(ms) | 6.96~7.23 | 9.08~9.32 | 11.21~12.16 | 12.83~13.89 |
4)压测结论
-
压测的流量(220 k/min)为目前 his 真实流量(73 k/min)的 3 倍,测试结果足够体现真实场景。
-
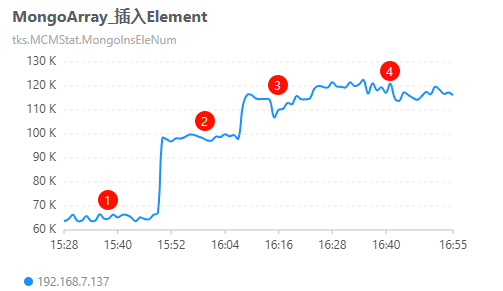
当测试服务(Store)从 3 个增加到 4 个时,读写量增加不明显(如下图示意),可以认为达到了性能瓶颈。
-
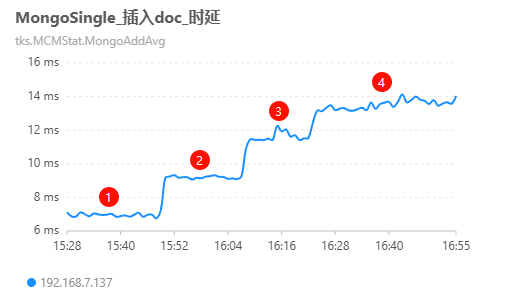
随着读写量的增加,GSS的性能表现逐步下降,具体表现为读写删的时延逐步提升(如下图示意)。
-
在相当压力下,GSS 中的 Mongo 模型均能表现出不错的读写性能(时延均在可接受范围内)。
-
ModelSingle 模型插入时会导致操作成倍增加。
当前插入的逻辑为:插入新doc,查询是否超过maxlen,逐条删除截断长度外的doc。
-
【占位】
占用空间
以下数据统计,均是基于本文前面介绍的业务结构统计的,Document 示例见前面。
在执行完上述所有测试后,对 MongoDB 中文档、索引的占用空间大小进行统计。
1)数据大小
| 有效数据/条 | Array的Data大小 | Single的Data大小 | Array索引 | Single索引 |
|---|---|---|---|---|
| 500W | 538.696 MB | 691.637 MB | 6.692 MB | 988.020 MB |
| 5000W | 5.387 GB | 6.934 GB | 62.976 MB | 5.568 GB |
因为 ArrayModel 与 SingleModel 的数据结构不同,因此在有效数据相同的情况下,其文档数量是不同的。在有效数据为 5000W 条的情况下:
- ArrayModel:50W 个 Document(数组的 maxLen 为100)
- SingleModel:5000W 个 Documen
2)占用磁盘空间
| 有效数据/条 | Array-doc占用 | Single-doc占用 | Array-总磁盘占用 | Single-总磁盘占用 |
|---|---|---|---|---|
| 500W | 132.2 MB | 196.5 MB | 156.790 MB | 589.983 MB |
| 5000W | 1.3 GB | 2.2 GB | 1.411 GB | 7.806 GB |
ArrayModel 与 SingleModel 的数据结构不同,导致其doc平均占用磁盘空间(AvgSize)也是不同的:
- ArrayModel:10.3KB
- SingleModel:138B
3)结论
- 数据大小:SingleModel 为 ArrayModel 的 1.3 倍左右。
- 索引大小:
- ArrayModel:索引为文档大小的 1.24%;
- SingleModel:索引为文档大小的 142.85 %;
- SingleModel 内存占用为 ArrayModel 的 147 倍。
- 整体磁盘占用空间:SingleModel 为 ArrayModel 的 3~6 倍(主要是索引导致的)。
- 整体结论:从多维度来看,ArrayModel 均比 SingleModel 节省资源,尤其是内存资源(索引占用)。
结论
在 “最近N场” 的业务场景下,ArrayModel 整体表现均优于 SingleModel。
SingleModel 适合的业务场景:
- 查询时不需要聚合,单条指向型查找。例如:将
"userid"+"gameid"+"mpid"设为唯一索引,查询的时候也传入这三个值,便可获得唯一的 document。 - value 内容远多于索引。索引占用的是内存,value 占用的是磁盘。因此 value 越多,性价比越高。而 ArrayModel 在这种情况下可能会导致 doc 超过 5MB 达到上限,或者是大 key 导致倾斜。
ArrayModel 适合的业务场景:
- 批量查询,返回的是个 array。例如查询某个用户在某场比赛的最近 N 场的战绩。
- maxLen 较大。当 maxLen 超过 25 时,ArrayModel 的综合性能均优于 SingleModel。
- value 内容不多。当 value 的字段只有几个时,ArrayModel 更适合。
发现的问题
1)MongoSingleModel 重复键值导致插入失败
-
MongoDB数据库唯一键:userid_1gameid_1_mpid_1_updateAt-1
-
updateAt字段说明:bson_data 格式,由 MongoConnMngr 自动生成,示例如下:1 2 3
"createAt": { "$date": "2025-01-21T07:59:52.117Z" }
-
现象:高并发(11 万/min)下,生成的
updateAt字段可能会重复,导致插入失败。 -
影响:实际业务场景下,不会出现 1 ms 写入多次的情况。因此,此问题可忽略。
2)插入时截断
GSS 中的两个新 Mongo 模型均需在插入时进行截断:
- MongoArrayModel:插入(或查询)时,需要筛选出 Array 中 超过 TTL 的 Element ,执行删除。
- MongoSingleModel:插入(或查询)时,需要筛选出 超过 maxLen 的 Document,执行删除。
问题:上述操作均会将 MongoDB 的 ops 放大至少 3 倍。
插入/查询时截断的对比
插入时截断:(目前GSS的插入操作不是异步的)
- 优点:
- SingleModel:保证 collection 整体数据量不会成倍增加。
- 缺点:
- HIS是一个高写低读的系统,截断操作会增加ops。写入时执行截断,会导致ops大量增加。
查询时截断:
- 优点:
- ArrayModel:实时保证查询时不会返回已经过期的索引。
- HIS是一个高写低读的系统,在查询时截断,对MongoDB的ops负担影响并不明显。
-
缺点:
-
执行截断的频次较低,导致单次截断时,过期数据较多。会导致查询时延大量增加。
(可通过先返回结果,然后再异步删除的方式,优化效率)
-
3)单表最大数据量
DBA建议单表最大数据为千万级,因此本次测试的最大数据量未达到亿的级别。
若后期评估某业务的数据量会达到亿级别,应采取分表,或按照userid分段分表。
4)过期时间
本文涉及到的两个模型均需将 “createAt” 字段设置为 TTL 索引,但本次并未针对 TTL 进行相关测试。
后续可以补充:
- 两模型在设置了TTL,并在有TTL批量过期时,“增删改查” 4个基本功能的延迟变化。
- 两模型利用定时任务过期数据,效率怎样,不同数据量对效率影响如何,两个模型是否有效率差异。
5)压测时性能下降
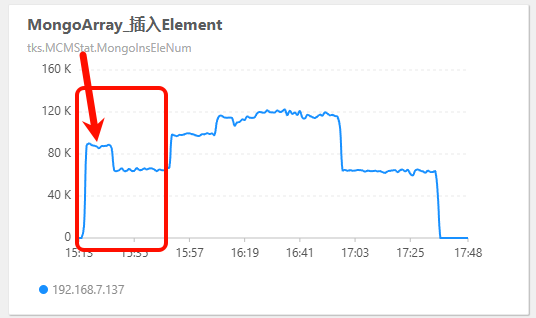
如上图所示,在压测的第一阶段(仅部署了一个测试 Store 时),在运行到一段时间后,整体性能会突然下降。
原因不详。